

近年来随着人工智能与数字人文领域的交叉融合不断深入,艺术风格智能识别、文博藏品数字化分类、艺术史大规模量化研究等应用需求持续攀升,但行业内长期缺乏标注维度丰富、样本覆盖全面的标准化艺术数据集,成为制约相关技术落地的核心瓶颈之一。作为全球数字人文研究领域的顶尖机构,丹麦奥胡斯大学人文计算中心(Center for Humanities Computing Aarhus)长期专注于用计算技术赋能文化遗产活化与人文学科研究,本次推出的wikiart_benchmarking数据集正是为填补这一行业空白打造的专项训练基准。
据公开信息显示,wikiart_benchmarking是一款覆盖画作图像与全维度结构化元数据的专业艺术数据集,总大小约为15.08GB,共包含33595个训练样本。每幅画作样本均附带三类核心标注信息:艺术家标签覆盖从鲍里斯·库斯托季耶夫到托马斯·庚斯博罗等横跨不同创作时期、不同创作流派的113位知名艺术家;流派标签包含抽象画、城市景观、人物画等10个主流画作品类;风格标签则覆盖抽象表现主义、新艺术运动、巴洛克等20种典型艺术风格。除此之外,数据集还额外提供原始索引、过滤后索引、各分类标签字符串表示等辅助字段,可大幅降低研究人员的数据预处理成本,支持直接调用开展相关训练任务。
从应用方向来看,该数据集可广泛适配多类艺术领域AI任务与产业落地场景:在学术研究层面,研究人员可基于该数据集开展艺术风格流变量化分析、艺术家创作脉络溯源、艺术作品真伪辅助鉴别等数字人文研究,突破传统艺术史研究的样本量限制;在文博产业层面,依托该数据集训练的AI模型可支撑海量馆藏艺术品的自动分类标注、智能导览识别等功能,大幅降低文博机构数字化运营的人工成本;在数字创意领域,该数据集可用于训练AI艺术创作的风格控制模型,提升生成作品的风格匹配度,也可为文创产品开发、艺术内容个性化推荐提供数据支撑。
作为艺术领域为数不多的公开标准化基准数据集,wikiart_benchmarking的发布不仅降低了AI艺术领域的研究门槛,也为文化类数据的规范化标注、开放共享提供了可参考的实践样本,对推动跨学科研究融合、助力文化数据要素价值释放、加快文化遗产数字化活化进程均有积极作用。
Dataset card内容:
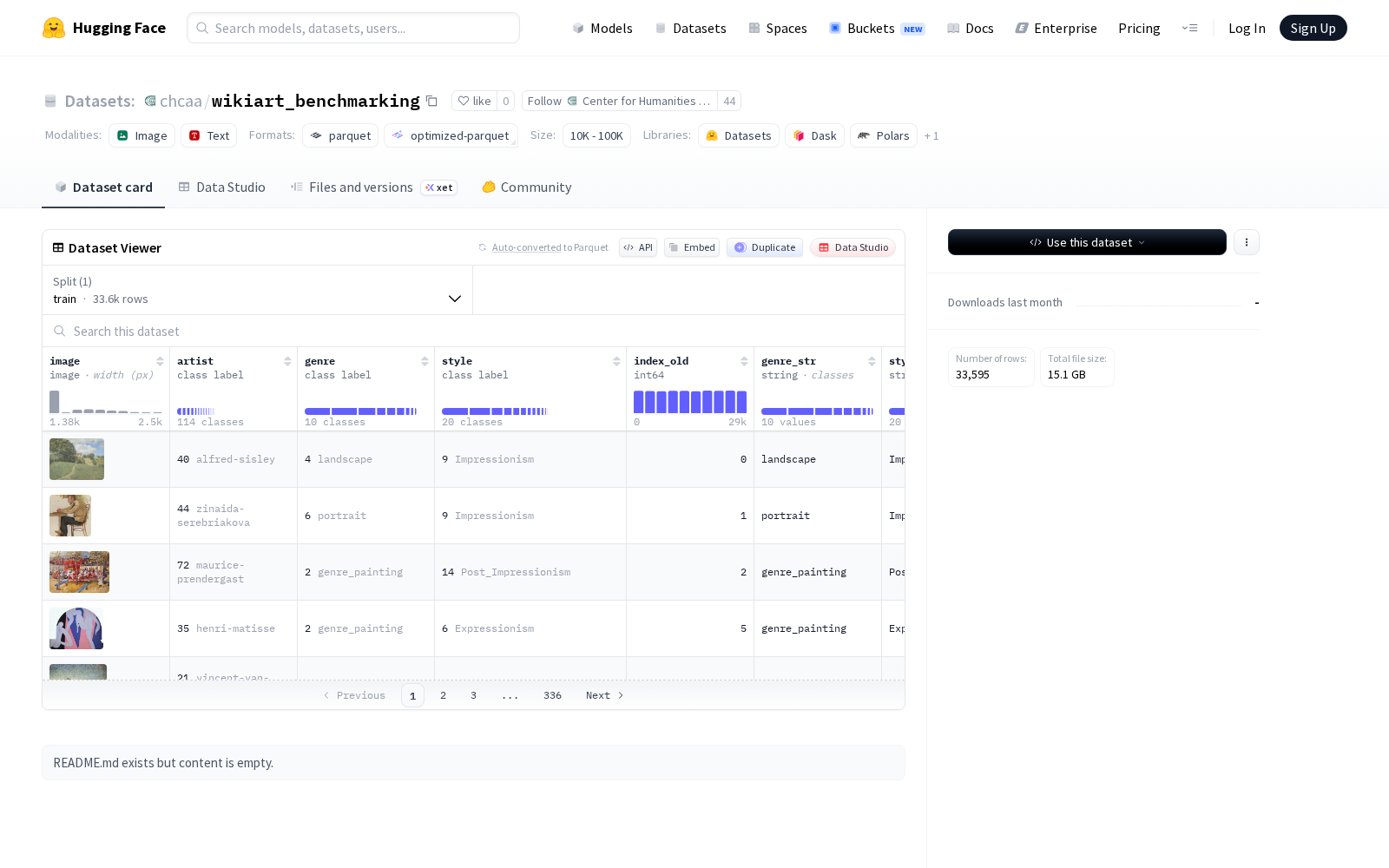
Files and versions内容:



_1769672084863.jpg)