

当前多模态大模型技术迭代进入深水区,视频理解领域的时空关联推理、跨模态问答能力一直是行业公认的技术难点,而标注维度完整、时空对应精准的高质量训练数据缺口,是制约相关技术落地的核心瓶颈之一。作为全球领先的企业级云计算与AI研发厂商,Salesforce近年在多模态大模型、行业AI应用领域持续投入研发,本次推出的ST-Evidence-Instruct数据集正是其在多模态训练数据领域的最新落地成果。
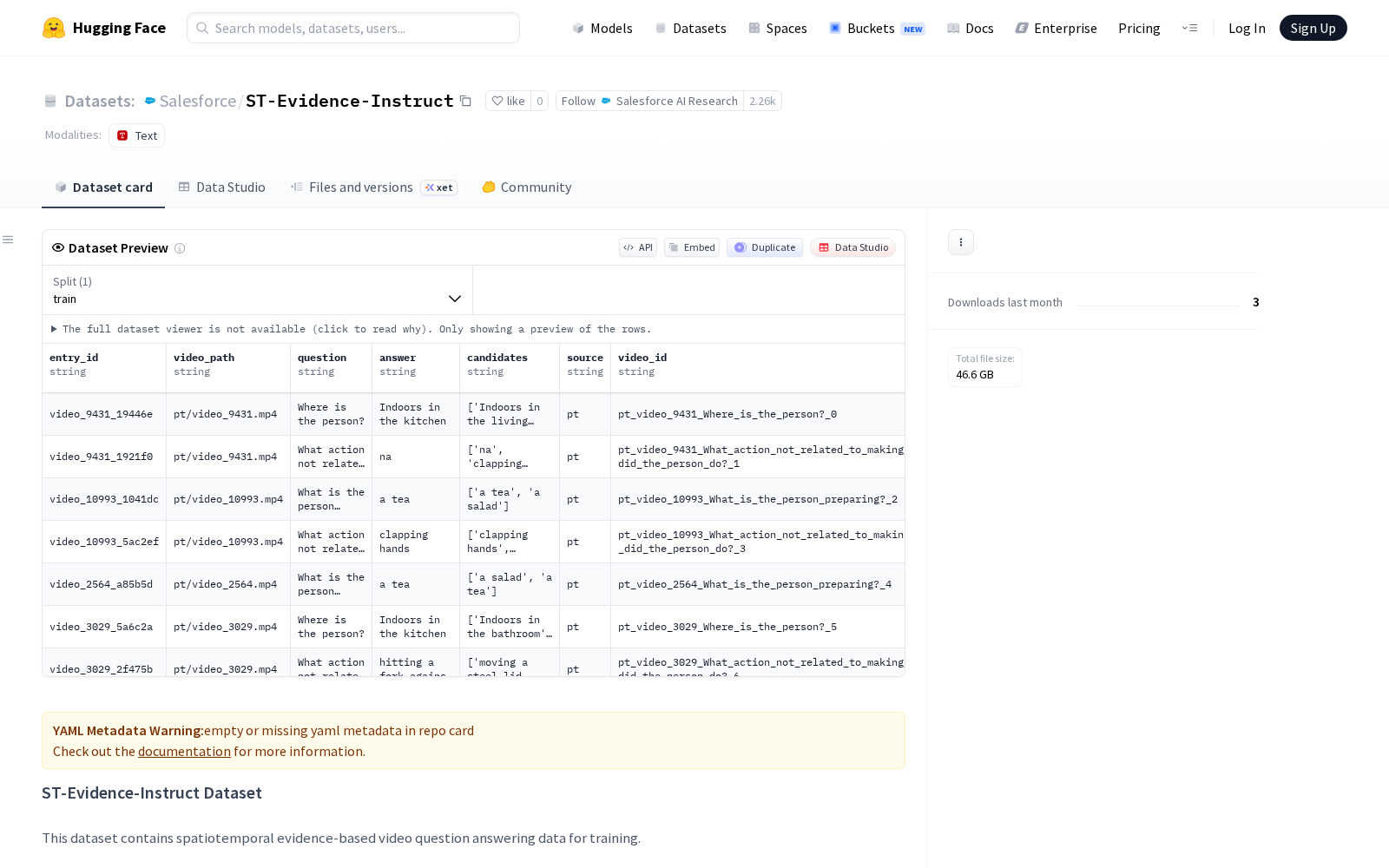
ST-Evidence-Instruct是一款基于时空证据的专业视频问答数据集,核心用于训练视频时空推理、多模态问答类AI模型。该数据集依托Google Gemini大模型生成,标注环节引入了Meta Platforms, Inc.推出的Segment Anything Model 3 (SAM 3)能力提升标注精度,整体分为gen_mask和gen_qa/vicas两大组成部分。其中gen_mask部分包含约20k样本,均源自CLEVRER视频数据集,通过GroundingDINO生成空间掩码,覆盖6fps的视频帧、经GroundingDINO优化的边界框级空间掩码、时间证据注释和配套问答对,该部分样本侧重训练模型建立“视频帧-空间对象-时间节点”的三元关联认知,可有效解决传统视频问答模型普遍存在的时空错位、对象识别混淆等问题。gen_qa/vicas部分包含141k样本,源自ViCaS视频数据集,通过Gemini与通义千问(Qwen)大模型协同生成问答内容,覆盖多选题、时间段注释、空间掩码引用、答案候选等多元标注维度,可满足不同复杂度的多模态问答模型训练需求。本次发布的数据集文件结构清晰,配套提供了详细的元数据和注释文件,方便研发团队快速调用,同时遵循CC-BY-NC 4.0许可协议,非商业用途的研发机构、创业团队均可免费获取使用,大幅降低了相关领域的研发门槛。
从行业应用价值来看,ST-Evidence-Instruct数据集的落地,为多模态AI领域的视频时空推理任务提供了统一的高标注基准,未来可广泛应用于多个产业场景的AI研发:智能安防领域可用于训练异常事件溯源、场景问答类应用;无人驾驶领域可用于训练车载视觉系统的动态场景推理能力;智能家居领域可用于提升智能终端对用户行为的理解与交互响应精度;此外在泛娱乐内容审核、教育实验视频智能答疑、工业视觉缺陷溯源等场景,该数据集也具备较高的训练应用价值,将进一步推动多模态视频理解技术从实验室走向产业落地,为全球数字经济领域的AI应用创新提供数据支撑。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)