

在数字人文与AI文博融合发展的当下,垂直文化领域的高质量标注数据集,已成为支撑艺术数字化研究、文化AI模型落地的核心基础设施。近日,丹麦奥胡斯人文计算中心(Center for Humanities Computing Aarhus)—— 全球知名的数字人文领域研究机构,长期专注于文化遗产数字化、人文知识图谱构建与公共文化数据开放工作—— 正式发布了名为wikidata_benchmarking的艺术领域结构化基准数据集,该数据集于2026年5月8日率先在全球最大的AI开源社区HuggingFace上线,面向全球研究者、开发者开放使用。
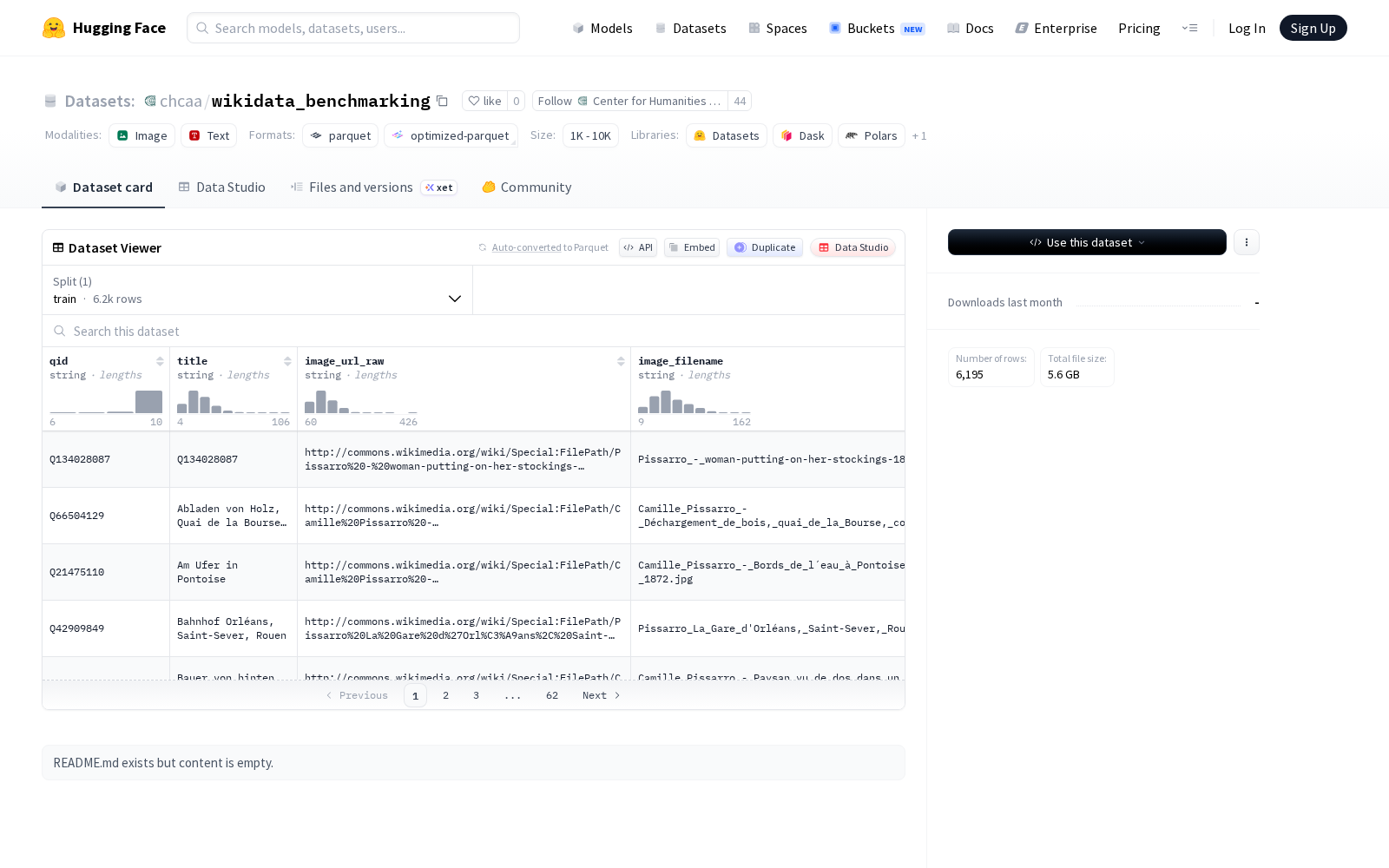
据公开信息显示,wikidata_benchmarking数据集共包含6195个标注完成的艺术作品训练样本,总数据量约5.3GB,下载大小约5.2GB,覆盖了艺术作品全维度的元数据字段,具体包括:关联维基数据全量知识图谱的唯一标识符(qid)、作品标题(title)、原始图像资源链接(image_url_raw)、创作时间(inception)、收藏机构与收藏地信息(collection、location)、创作材料(material)、艺术流派(genre)、作品物理尺寸(height_cm、width_cm)、作品描绘主题(depicts)、馆藏编号(inventory_number)、维基数据条目链接(wikidata_url)以及艺术家(artist)标签。其中艺术家标签共覆盖18个细分类别,包含阿尔弗莱德·西斯莱、贝尔特·莫里索、克劳德·莫奈等多位印象派代表艺术家的作品标注,同时数据集配套提供对应艺术作品的高清图像数据,可满足多模态AI模型的训练与评测需求。
作为基于维基数据权威条目构建的标准化基准数据集,wikidata_benchmarking可为多个领域的研究与落地提供数据支撑:在AI技术落地层面,可用于艺术作品分类模型、艺术品图像识别模型的训练与效果评测,支撑文博场馆智能导览、艺术品辅助鉴真、数字藏品版权校验等场景的功能落地;在学术研究层面,可为艺术史学者提供标准化批量分析样本,支撑不同流派创作风格演变、艺术材料发展脉络等方向的量化研究;在文化数字化层面,也可为数字策展、AIGC艺术创作的逻辑校准提供数据参考,填补了艺术领域公开基准数据集的供给空白,也为全球公共文化数据的开放共享、创新应用提供了可参考的范例。该数据集目前适用于艺术分类、图像识别、艺术史研究等多类任务。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)