

随着具身智能、通用人形机器人赛道进入快速落地期,高质量、多场景、标准化的指令标注训练数据已成为制约行业发展的核心瓶颈之一。作为全球领先的非营利性AI研究机构,Allen Institute for AI(艾伦人工智能研究所,由微软联合创始人保罗·艾伦创立,长期聚焦大模型、多模态AI、具身智能等前沿领域的开源研究)本次上线的全新标注数据集,为行业公共训练资源体系提供了重要补充。
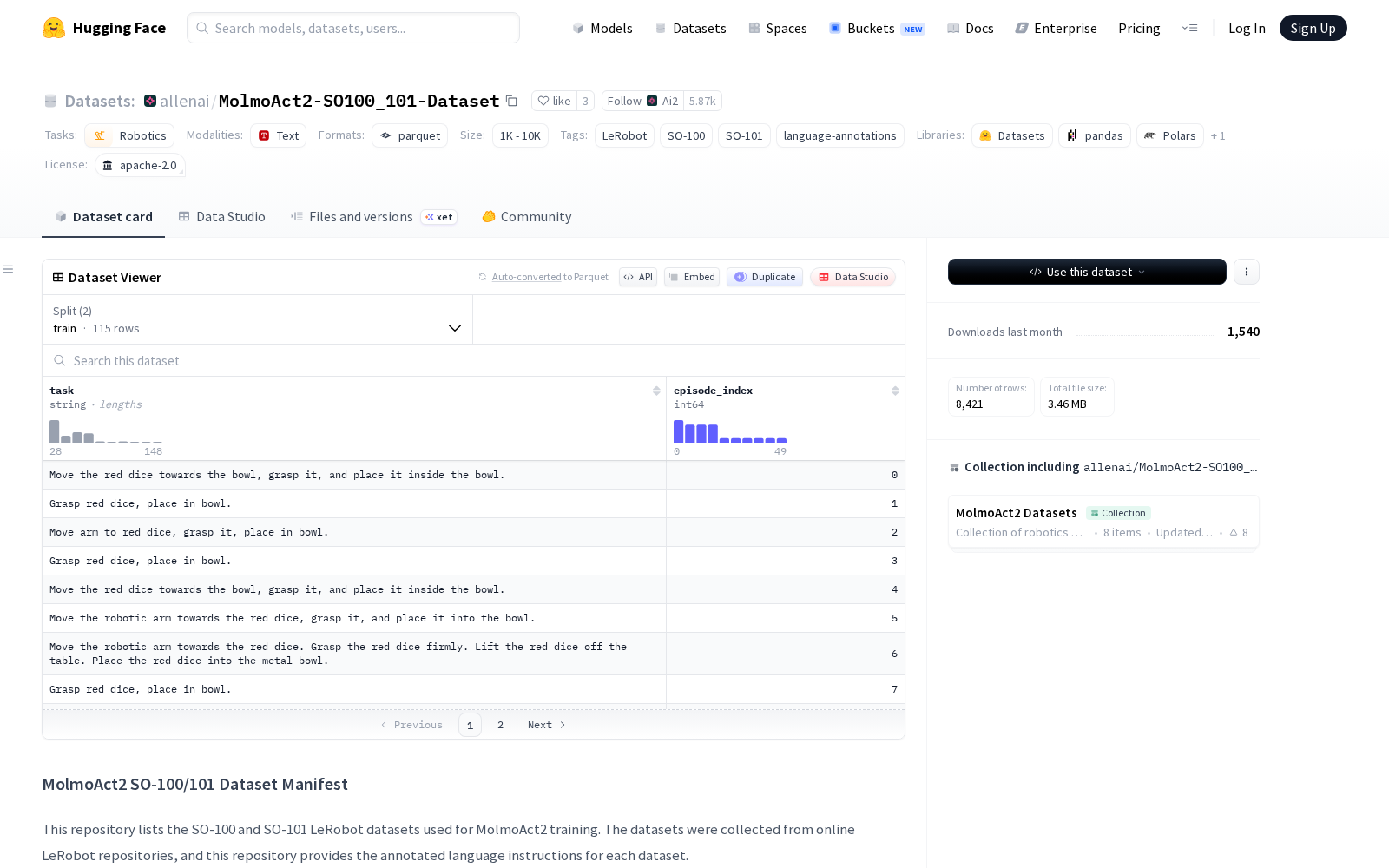
本次发布的MolmoAct2-SO100_101-Dataset,由SO-100和SO-101两大LeRobot子数据集构成,全部数据来自开源LeRobot仓库的公开贡献内容,覆盖377名贡献者提交的1220个不同场景的机器人操作仓库,所有样本均配套了标准化的语言指令标注。据公开信息显示,该数据集的语言标注内容统一存储于language_annotations/目录下的tasks_annotated.parquet文件,按episode_index建立索引,通过task列记录每集操作对应的标注指令。为适配现有开发者工具链,数据集兼容标准LeRobot加载器,可通过task_index直接解析调用语言指令,若无对应标注行则自动回退到标准LeRobot任务格式,无需开发者额外适配。数据集整体采用用户名称-仓库名称的分层组织结构,每个独立仓库下均配套独立的tasks_annotated.parquet标注文件,便于开发者按需调取特定场景的训练数据。
作为专门面向机器人指令学习与语言任务标注领域的开源数据集,MolmoAct2-SO100_101-Dataset的应用场景覆盖具身AI研发的多个核心环节:首先可用于通用人形机器人的自然语言指令理解训练,多来源的用户标注数据可帮助模型适配不同人群的语言表达习惯,提升家用、商用、工业等多场景下的指令识别准确率;其次可支撑跨域机器人任务的模型迁移训练,千余个不同场景的操作样本可降低模型在不同场景下的适配成本;此外统一的标注格式也可作为机器人语言任务标注的基准参考,帮助行业建立标准化的标注规范。
当前全球数据要素市场中,AI训练数据尤其是具身智能领域的高价值标注数据属于稀缺资源,多数中小研发团队面临训练数据量不足、标注不统一的痛点。本次艾伦人工智能研究所开源该数据集,一方面为中小研发团队降低了具身AI的训练门槛,另一方面也为多源开源机器人数据的整合、标注、流通提供了可参考的样本,对推动具身智能产业的落地进程有重要的公共价值。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)