

随着大模型商业化落地进程加快,“黑盒”属性带来的可解释性不足问题,已经成为制约AI技术合规落地、安全应用的核心瓶颈,其中训练数据对模型输出的影响追溯,是大模型归因领域的核心研究方向。长期以来,该领域缺乏标准化、高置信的基准数据集,导致不同研究的结论难以横向对比、实验可复现性不足,极大拖慢了技术迭代效率。近日,全球知名开源大模型研究组织EleutherAI正式上线bergson-magic-scores-gpt-2数据集,为该领域的研究突破提供了重要的基础支撑。
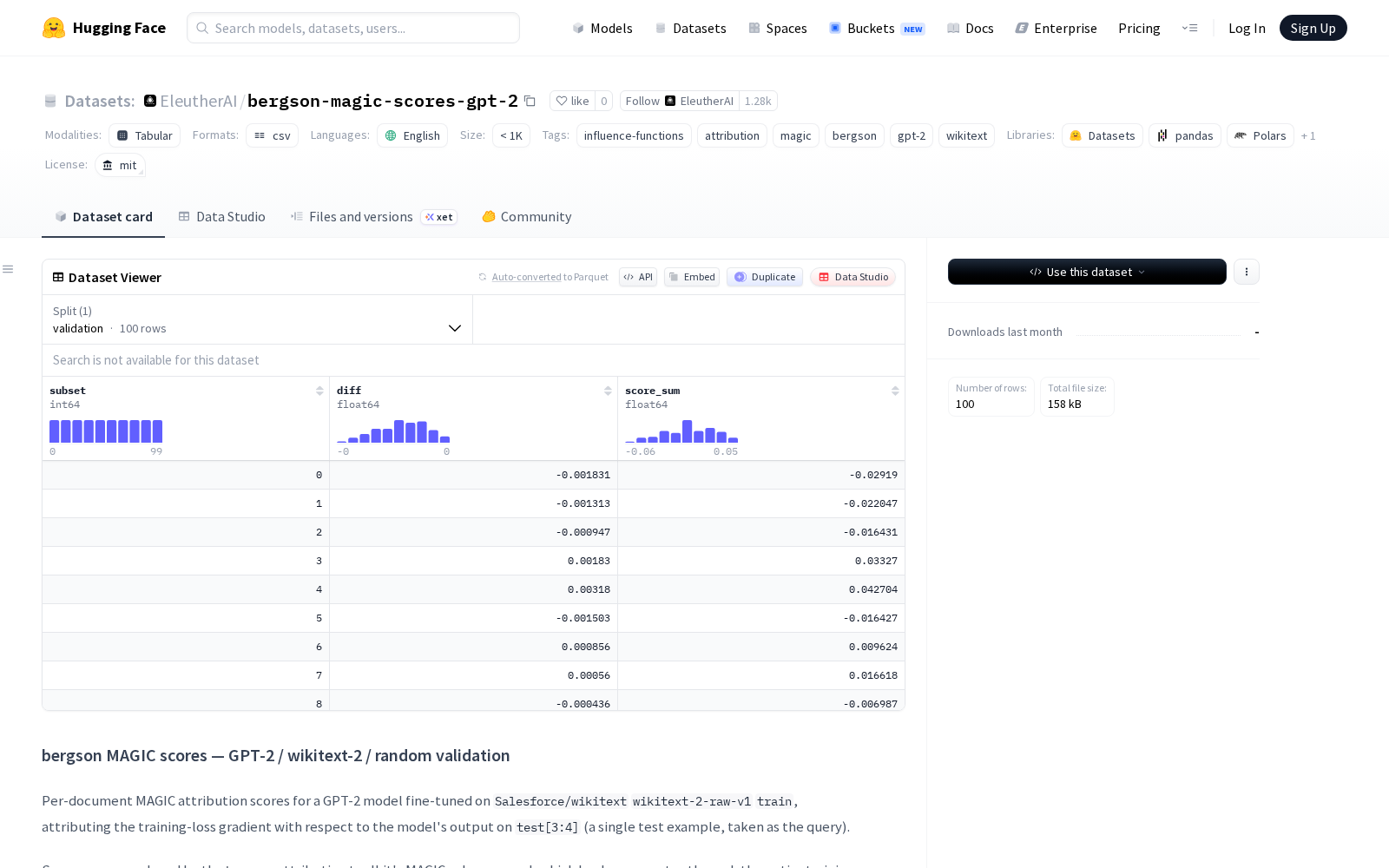
据介绍,本次发布的bergson-magic-scores-gpt-2数据集于2026年5月8日首发于HuggingFace平台,面向全球研究者开放使用。该数据集包含针对在Salesforce开源wikitext数据集上微调的GPT-2模型的每文档MAGIC归因分数,所有分数均通过bergson归因工具包的MAGIC子命令生成,核心作用是量化每个训练文档对模型在特定测试示例上输出结果的影响程度。从数据构成来看,数据集核心包含一个形状为 (36718,) 的torch.float32格式张量文件scores.pt,以及用于验证结果的CSV文件,研究者可直接调用开展相关实验,无需额外进行耗时耗力的标注工作。官方公布的验证结果显示,该数据集标注的MAGIC分数与留k出训练损失差异之间存在高度相关性,Spearman ρ系数达到+0.9731,数据标注准确性处于行业领先水平,具备作为行业基准数据集的可靠性。
从应用场景来看,该数据集可覆盖大模型研究领域的多个核心方向:一是可用于大模型归因算法的验证与迭代,研究者可基于该标准化数据集对比不同归因算法的准确率,降低研究过程中的数据集制备成本,提升研究结论的可信度;二是可支撑训练数据影响评估研究,通过归因分数分析不同类型训练数据对模型输出的权重影响,为大模型训练数据筛选、有害内容追溯、偏见来源定位提供研究支撑;三是可服务于大模型合规与安全技术研发,为训练数据版权追溯、模型输出风险溯源等技术的研发提供实验基础;此外,该数据集还可用于支撑大模型训练流程优化研究,帮助研究者通过归因结果反向调整训练数据配比、微调策略,提升模型训练效率与输出质量。
作为全球最具影响力的开源大模型研究组织之一,EleutherAI本次发布的专用归因数据集,填补了大模型归因领域标准化基准数据集的空白,对推动大模型可解释性技术迭代、加速AI合规落地进程具备重要意义,也为后续更大参数规模大模型的归因数据集研发提供了可参考的技术范式。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)