

随着大模型多轮对话能力、可解释性与安全治理成为行业研发核心方向,具备全链路元数据的高质量标注对话数据集正成为AI研发领域的稀缺资源。作为全球知名的非盈利AI数据资源机构,LAION eV此前推出的LAION-5B等系列数据集曾为生成式AI产业的快速发展提供了核心数据底座,其发布的公开数据集因标注规范、场景覆盖全面被全球数千家研发机构与高校采用。
2026年5月8日,LAION eV正式在HuggingFace平台首发rl__24GPU_base_excl_timeouts__exp_rpt_pymethods2test-large__GLM-4_7-swesmith-san__40-0-traces数据集,聚焦多轮对话系统研究与大模型训练场景。据公开信息显示,该数据集共包含21,391个训练样本,总大小约183MB,仅设置单训练集划分,数据文件存储路径为data/train-*,方便研发人员直接调用。
该数据集的字段设计覆盖了对话全链路的核心维度,每个样本共设12个特征字段:其中对话内容(conversations)包含content和role字段,明确区分交互过程中的用户侧输入、助手侧输出信息,可直接用于对话逻辑的训练与校验;代理标识(agent)、模型名称(model)、模型提供商(model_provider)三个字段,可支撑不同基座模型、不同对话代理的行为对比研究;日期(date)、任务类型(task)、场景片段(episode)字段,覆盖了不同时间、不同任务场景下的对话特征,可用于多场景对话能力的泛化训练;运行ID(run_id)、试验名称(trial_name)字段保留了试验全链路标识,方便研究人员复现相关试验流程;结果(result)、指令(instruction)和验证输出(verifier_output)字段则提供了明确的对齐标注,可直接用于RLHF(人类反馈强化学习)、模型指令遵循能力训练等场景。
从应用场景来看,该数据集可广泛用于三大类AI研发方向:一是多轮对话系统开发,可帮助优化大模型长上下文记忆能力、多轮指令遵循能力,降低长对话场景下的信息遗忘、逻辑跑偏等问题;二是模型行为分析,通过对比不同模型在同一场景下的输出差异,可识别大模型幻觉、安全风险输出的发生规律,为大模型可解释性研究、安全治理体系建设提供数据支撑;三是多任务学习,覆盖不同任务类型的标注样本可用于训练通用对话代理的跨场景适配能力,提升大模型在垂直领域的落地效率。
该数据集的发布,进一步丰富了细分化AI训练数据集的供给,为全球研发团队降低了对话数据的采集、标注成本,也为数据要素市场中AI训练数据的标准化建设提供了参考范本。
查看rl__24GPU_base_excl_timeouts__exp_rpt_pymethods2test-large__GLM-4_7-swesmith-san__40-0-traces
Dataset card内容:
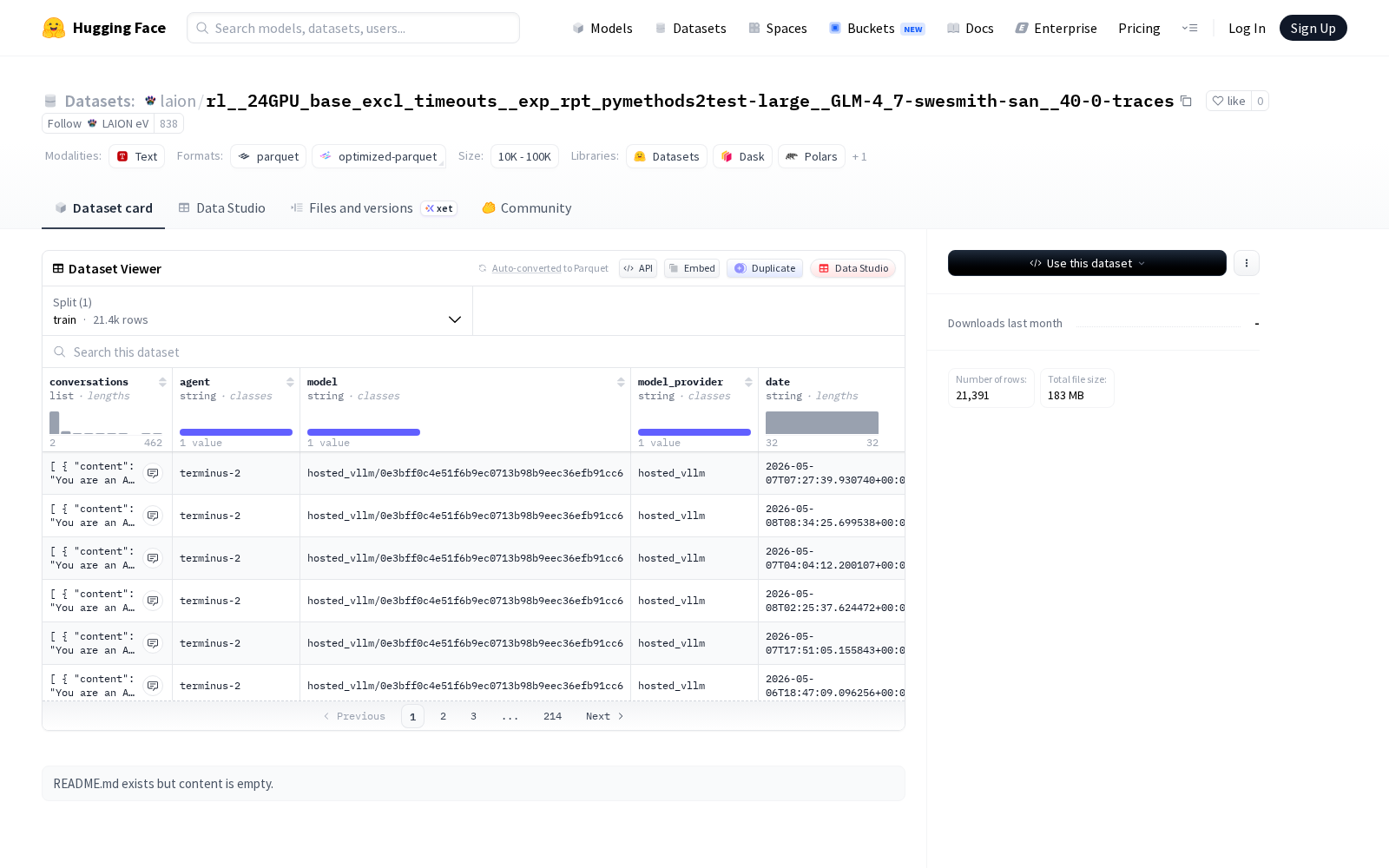
Files and versions内容:



_1769672084863.jpg)