

随着电商产业数字化进程加快,AI技术在商品管理、交易治理、用户服务等环节的落地需求持续攀升,而高质量、标注完备的垂类多模态数据集,是支撑电商AI模型研发与规模化落地的核心基础。全球AI计算龙头NVIDIA长期布局AI开源生态,为开发者提供从算力、模型到训练数据的全链路支持,此次发布的电商垂类数据集正是其开源生态布局的最新动作。
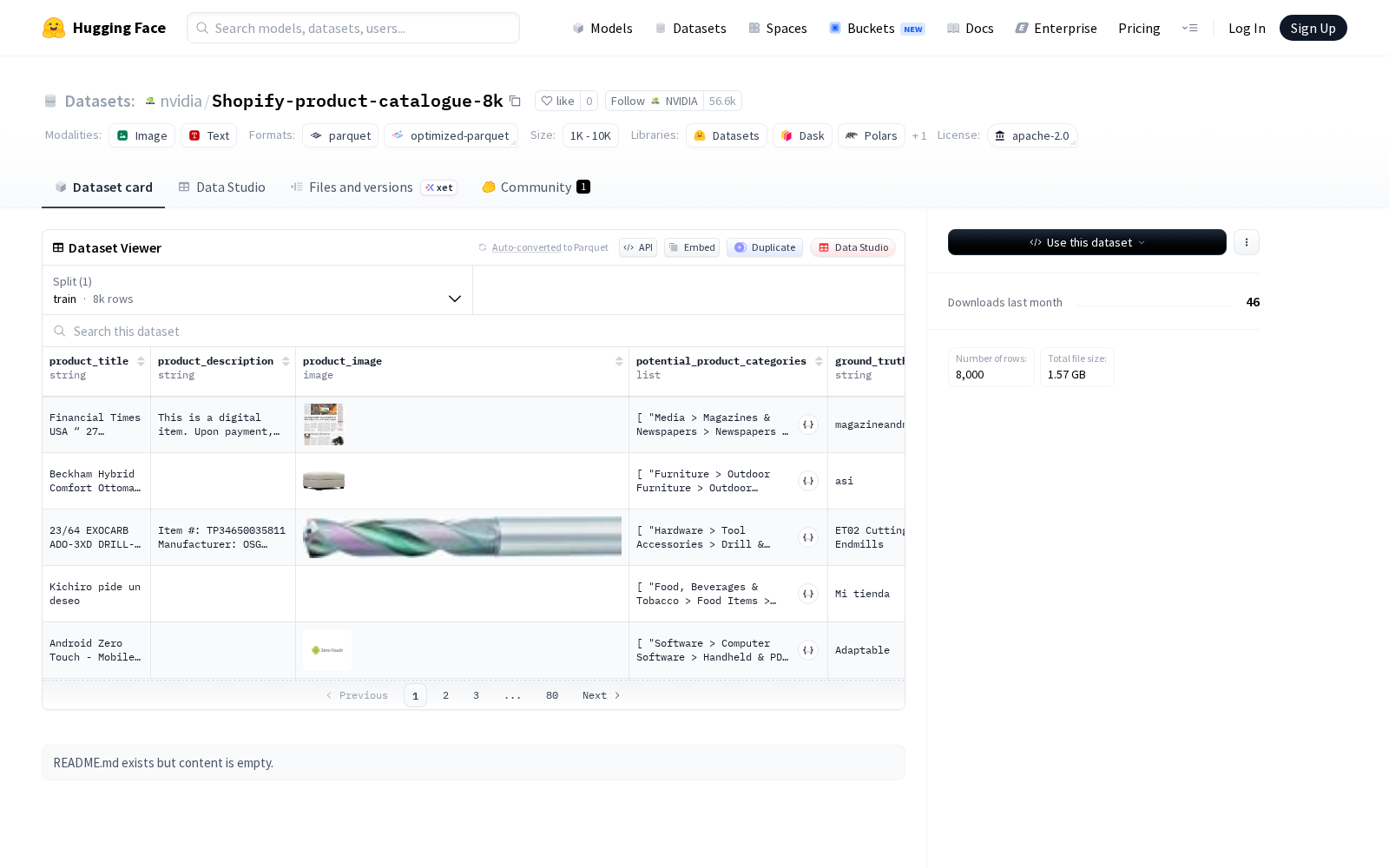
2026年5月7日,NVIDIA正式首发的Shopify-product-catalogue-8k商品信息数据集,采用开源友好的Apache 2.0许可协议,允许开发者免费使用、修改甚至用于商业场景,大幅降低了电商AI研发的数据源获取门槛。据公开信息显示,该数据集共包含8000个经过标准化标注的商品样本,总数据量1.63GB,下载大小约1.57GB,仅开放训练集分区。每个样本均覆盖多维度结构化标注信息:文本维度包含商品标题、商品描述字段,视觉维度包含对应商品图片,同时标注有潜在商品类别、真实品牌、是否为二手商品、真实商品类别4项核心业务标签,是目前少有的同时覆盖文本、视觉多模态数据与标准化业务标签的电商垂类数据集。
从应用方向来看,该数据集可广泛支撑电子商务领域的多模态AI任务研发:在电商平台商品管理场景中,可用于训练智能分类模型,实现新品上架自动匹配类目,替代人工审核环节,大幅提升商品上架效率;在二手交易、正品治理场景中,可用于训练二手商品检测、品牌侵权识别模型,帮助平台自动识别以旧充新、冒用品牌的违规商品,降低平台治理成本与用户投诉率;除此之外,该数据集还可用于多模态商品搜索、个性化商品推荐、商品内容自动生成等多个电商AI场景的模型训练,覆盖电商运营的核心环节。
当前全球数据要素市场建设持续推进,AI训练数据作为数字经济时代的核心生产要素,垂类领域的高质量标注数据缺口仍然较大,此次NVIDIA发布的开源电商数据集,不仅为全球AI开发者提供了优质的垂类训练数据源,也为电商产业的AI落地提供了重要的基础支撑,对于降低中小电商服务商、AI创业团队的研发成本,推动电商数字化转型向纵深发展具有积极意义。
查看Shopify-product-catalogue-8k
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)