

当前,生成式AI正从通用问答向长上下文多轮对话、AI Agent垂直落地的方向快速演进,高质量的场景化标注数据集,已经成为制约相关技术迭代效率、产品落地效果的核心瓶颈。尤其是同时覆盖对话内容、实验配置、模型元数据、执行结果的全链路数据集,在行业内供给相对稀缺,大幅提升了研发团队的测试与训练成本。
作为全球范围内极具影响力的AI开源数据集非营利机构,LAION eV此前推出的LAION-5B等大规模图文数据集,曾作为核心训练资源支撑了Stable Diffusion等多款现象级生成式AI产品的研发,其开源开放的数据集产品一直是全球AI研发群体的核心数据供给来源之一。
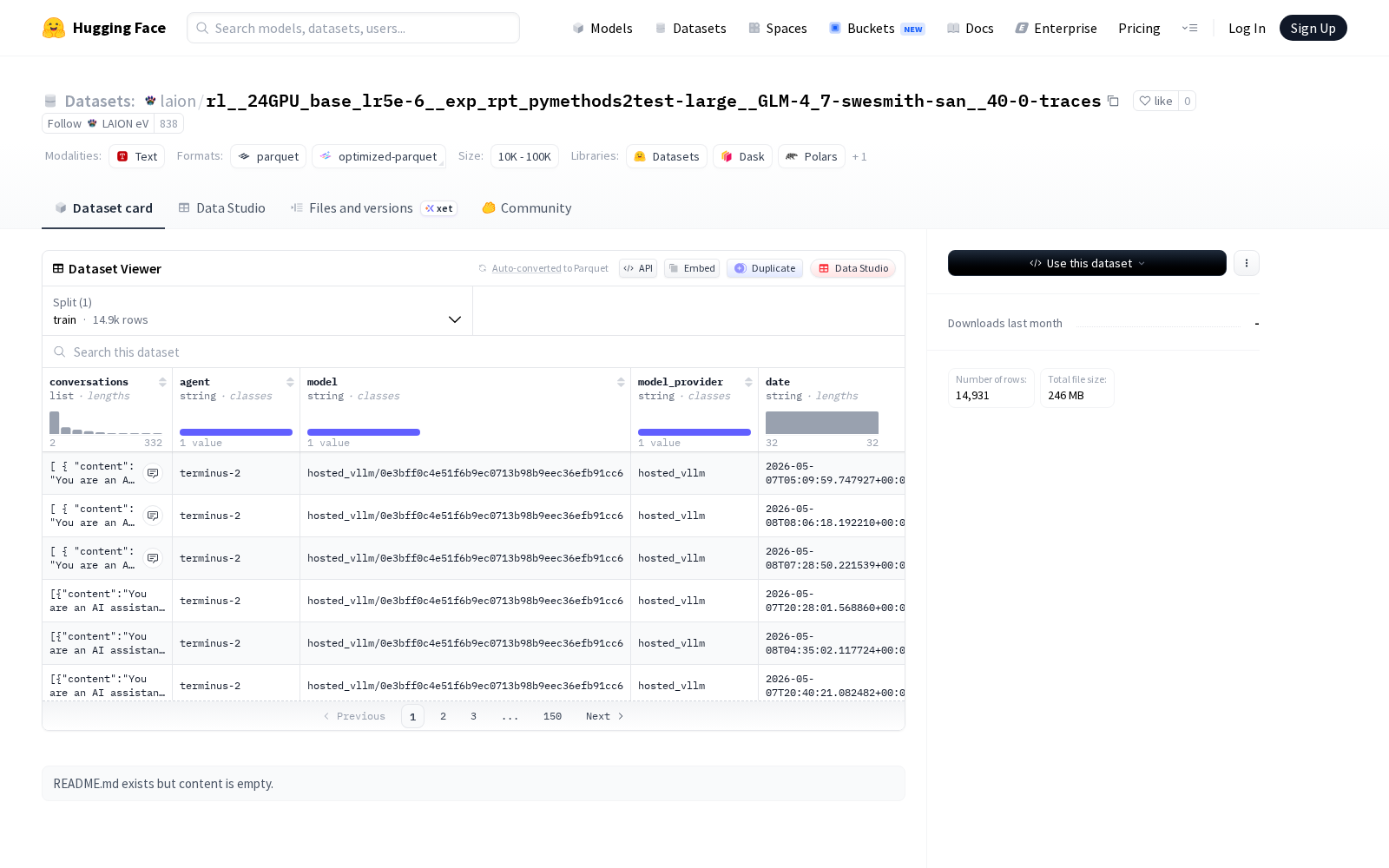
2026年5月8日,LAION eV正式在Hugging Face首发rl__24GPU_base_lr5e-6__exp_rpt_pymethods2test-large__GLM-4_7-swesmith-san__40-0-traces数据集,瞄准多轮对话系统训练、AI代理行为评估两大核心场景,为行业提供标准化的高质量数据支撑。
本次发布的数据集共包含14,931个训练样本,全部以结构化对话格式存储,标注维度覆盖了从对话内容到实验配置的全链路信息:核心字段包括带content文本和role角色标识的多轮对话内容(conversations列表)、代理信息(agent)、模型及服务商字段(model, model_provider)、时间戳(date)、任务标识(task)、全链路实验信息(episode, run_id, trial_name)、任务执行结果(result)、输入指令(instruction)以及验证输出(verifier_output)。不同于普通的对话数据集,本次发布的产品额外补充了实验环境、模型来源等核心元数据,无需研发人员二次标注即可直接用于不同配置下的AI模型对话表现对比研究。
从行业应用来看,该数据集可覆盖三大典型研发场景:其一可用于多轮对话大模型的微调训练,借助标注完整的长对话数据,研发团队可针对性优化大模型的上下文记忆能力、多轮对话逻辑一致性,提升智能客服、个人助理等对话类产品的交互体验;其二可用于AI Agent的行为评估测试,依托数据集中的任务标识、执行结果、实验配置字段,开发者可搭建标准化的智能体性能测试基准,验证不同参数配置下Agent的任务完成率、决策准确率,为智能体在办公辅助、工业调度、科研服务等场景的落地提供数据支撑;其三可用于大模型性能横向对比研究,数据集中自带的模型提供商、训练配置等元数据,为学界和产业界对比不同基座大模型的对话能力、任务执行能力提供了统一的测试样本集,可大幅降低行业重复构造测试集的研发投入。
作为数据要素市场的核心组成部分,AI训练数据集的供给能力直接决定了AI产业的迭代速度。本次LAION eV推出的垂直场景开源数据集,进一步丰富了全球AI研发群体的可用数据资源,降低了多轮对话、AI Agent领域的研发门槛,对推动生成式AI技术的普惠化发展、加快相关技术从实验室走向产业落地具有积极意义。
查看rl__24GPU_base_lr5e-6__exp_rpt_pymethods2test-large__GLM-4_7-swesmith-san__40-0-traces
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)