

近年来,多模态大模型(LVLM)技术快速迭代,在图文理解、跨模态翻译等领域的商业化落地进程不断加快,但针对“需依赖视觉信息才能完成语义消歧”的特殊场景,行业长期缺乏统一的标准化测试基准,导致不同模型的视觉消歧能力难以横向对比,多模态翻译的语义精准度提升缺乏统一的校验标尺。2026年5月4日,汉堡大学联合阿里巴巴团队共同构建的VIDA(Visually-Dependent Ambiguity)多模态机器翻译数据集正式在arXiv平台首发,瞄准视觉依赖性歧义解析这一细分研究方向,为相关技术研发提供高质量数据支撑。
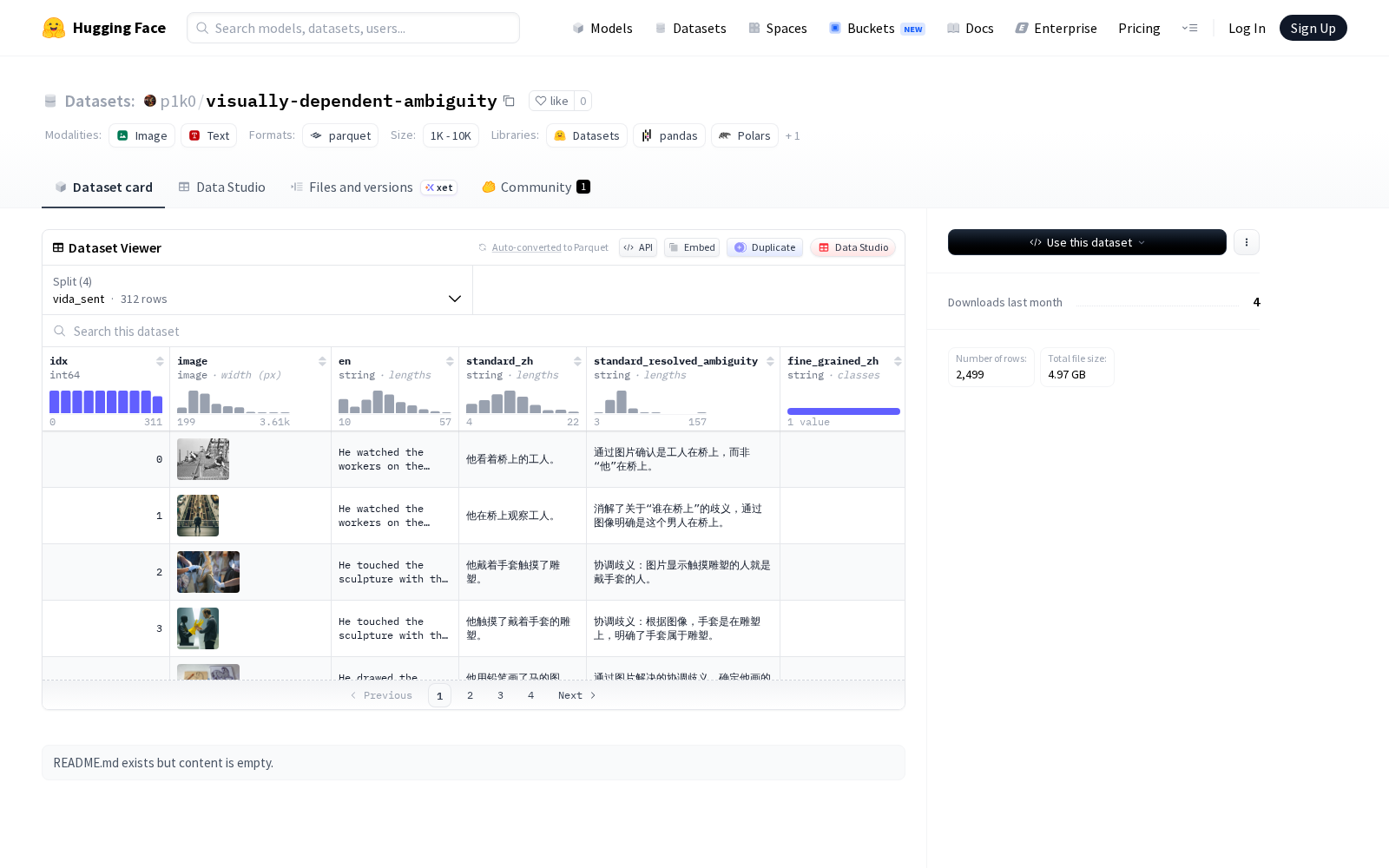
据介绍,本次发布的VIDA数据集共包含2500条经严格筛选的英中翻译实例,覆盖词级歧义、句级歧义、集体名词歧义三类核心应用场景,所有样本的语义判定均无法仅通过文本信息完成,必须结合对应视觉证据才能实现准确消歧,完全贴合真实世界中多模态翻译的典型痛点场景。为保障数据集的专业性和准确度,研发团队采用三阶段半自动化流程完成构建:首先基于GPT-4o和双大语言模型共识机制完成歧义样本的初筛,排除无需视觉信息即可消歧的普通样本;随后针对筛选后的歧义场景完成结构化翻译生成;最终所有样本均经过专业译员的人工校验,确保标注准确率符合科研级数据集要求。
作为行业内少有的聚焦视觉消歧场景的英中多模态翻译数据集,VIDA的核心价值在于为LVLM模型的视觉消歧能力评估提供统一的标准化测试基准,有望推动多模态翻译领域的语义精准度研究进入可量化、可对比的新阶段。从应用场景来看,该数据集可支撑多个垂直领域的多模态技术研发:比如跨境电商场景下的商品图文自动翻译,可解决同一个词汇对应不同品类商品时的语义偏差问题;跨境内容平台的图文内容本地化翻译,可提升文旅、科普等带图内容的翻译准确度;智能客服场景下的多模态交互翻译,可结合用户上传的图片准确理解用户诉求并给出对应翻译结果。从数据要素行业的角度来看,垂直场景高质量标注数据集是AI技术落地的核心底座,VIDA数据集的发布不仅填补了视觉依赖性歧义解析领域的基准数据空白,也为多模态翻译技术的商业化落地提供了重要的基础支撑,对推动多模态大模型的细分场景落地、完善多模态AI领域的数据供给体系都有积极意义。
查看VIDA (Visually-Dependent Ambiguity)
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)