

随着全球多语言数字化协作场景的快速扩容,自然语言转SQL(NL2SQL)作为降低非技术人员数据查询门槛的核心技术,其跨语言适配能力已经成为跨境企业、多语言公共服务领域的核心需求。但长期以来,面向英葡双语场景的NL2SQL专用评测数据集供给不足,不同研发团队的模型性能缺乏统一评估标尺,一定程度上制约了相关技术在拉美、伊比利亚半岛等葡语区域的商业化落地。
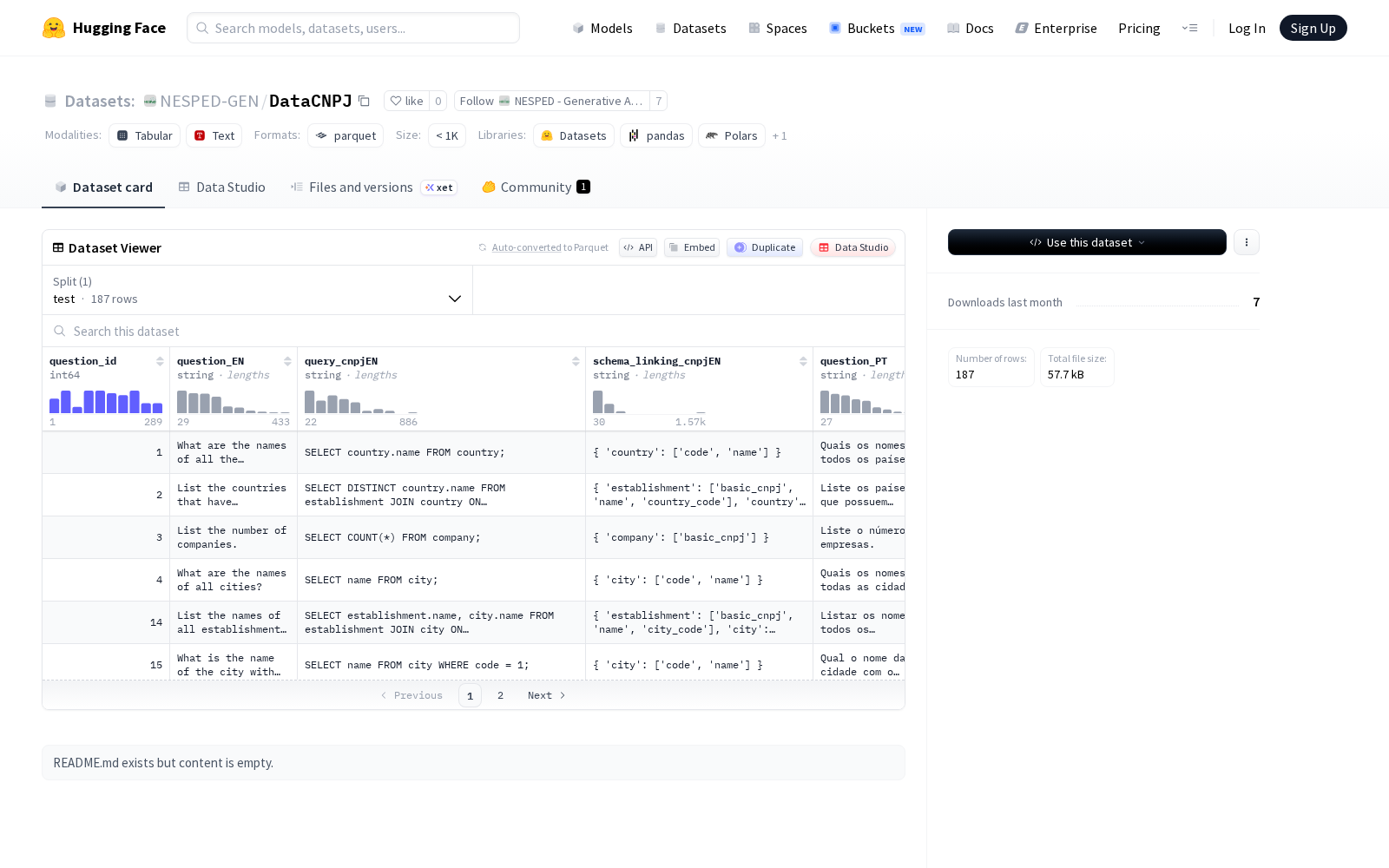
在此背景下,NESPED - Generative AI Reaserch本次发布的数据集DataCNPJ,正是针对英葡双语数据库查询场景打造的标准化测试基准。据公开信息显示,该数据集包含187个测试样本,采用单一测试集划分,总大小为219KB,包含10个结构化字段,核心覆盖双语(英语和葡萄牙语)数据库查询的全链路测试需求。每个样本包含唯一的问题ID、英文和葡萄牙语的问题文本、对应的数据库查询语句(query_cnpj)和模式链接信息(schema_linking),同时标注了样本是否为合成数据(synthetic)以及问题难度等级(hardness),特别适用于跨语言数据库查询系统的开发和评估。
从应用场景来看,DataCNPJ可覆盖多类英葡双语环境下的数字化需求:一方面可为跨国企业的内部数据查询系统开发提供测试基准,支撑企业打造支持英葡双语自然交互的ERP、供应链管理系统,让不同语言背景的运营人员无需掌握SQL语法即可快速调取业务数据;另一方面也可为公共服务领域的多语言数据查询平台提供性能评测依据,助力葡语地区的政务服务平台面向英语居民、跨境从业者开放自然语言查询社保、税务、商事登记等公共数据的能力。此外,该数据集也可作为大模型多语言能力评测的垂直场景补充,帮助大模型厂商优化英葡双语的语义理解与结构化数据查询能力。
行业人士指出,垂直场景专用数据集的供给是数据要素市场在AI研发领域落地的重要体现,本次DataCNPJ的发布填补了英葡双语NL2SQL领域的测试基准空白,将有效降低相关技术的研发评测成本,加速跨语言数据库交互技术在葡语区的落地进程,为多语言数字经济的互联互通提供基础支撑。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)