

当前,具身智能与服务机器人赛道正进入快速落地期,面向细分操作场景的高质量标注数据集,是训练机器人运动控制、视觉感知算法的核心基础资源,也是制约中小研发团队技术迭代效率的核心瓶颈之一。近日,机器人学习研究团队robot-learning-group47正式发布eval1_red_bowl19_new数据集,该数据集聚焦桌面红碗抓取的典型机器人操作场景,为相关领域的算法研发提供标准化的训练与验证素材。
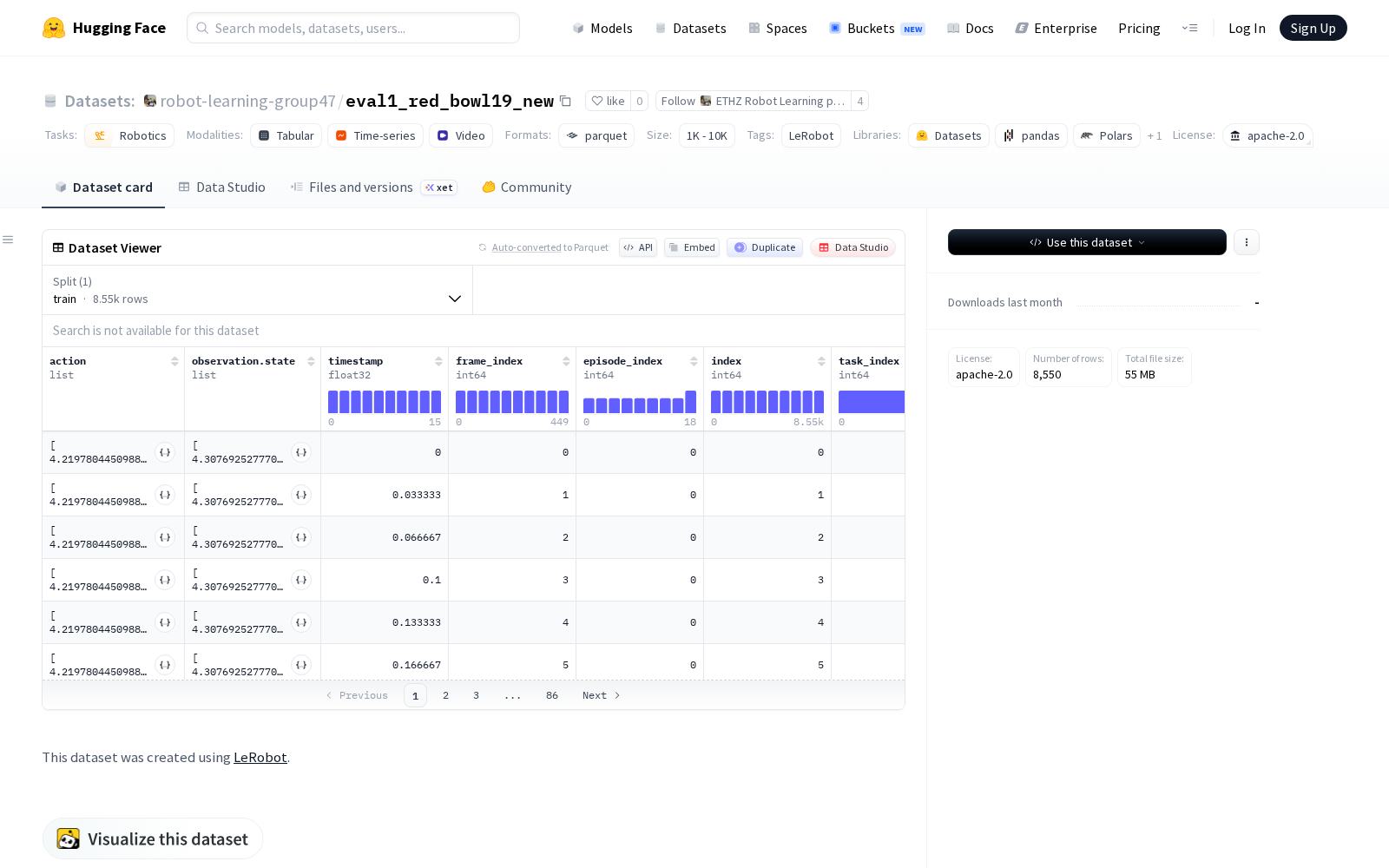
该数据集基于HuggingFace旗下开源机器人学习工具栈LeRobot构建,完整覆盖了机器人执行抓取任务过程中的多维度同步数据:全量数据集包含19个完整操作序列(episodes)、8550帧同步采集数据,包含30fps的RGB视频流、机器人动作与状态数据两大核心模块,总大小为100MB结构化数据文件与200MB视频文件,轻量化的体积便于研发团队快速下载部署。数据存储采用行业通用的parquet格式,内置动作、观测状态、图像、时间戳四类核心字段,可直接兼容主流机器人学习框架的数据输入标准。
从数据维度来看,该数据集的动作与观测状态模块覆盖shoulder_pan.pos、shoulder_lift.pos、elbow_flex.pos、wrist_flex.pos、wrist_roll.pos、gripper.pos六大维度,完整对应桌面级六轴机械臂的全部运动自由度,能够精准还原机械臂执行抓取动作时的运动轨迹、关节力矩与夹爪开合状态;图像模块为480x640分辨率的RGB同步视频,可为视觉感知算法提供清晰的场景观测素材。
从应用价值来看,这类包含“视觉输入-动作输出”完整映射关系的结构化数据集,可广泛应用于多个机器人研发场景:一是机器人运动控制算法的效果验证,研发人员可依托标准化的场景数据,快速比对不同轨迹规划、力位混合控制算法在同一抓取任务下的成功率、执行效率等核心指标,大幅降低算法验证的测试成本;二是视觉感知算法的训练迭代,可支撑小样本目标识别、动态场景抓取点定位、机械臂姿态估计等多类视觉任务的预训练与效果调优;三是端到端具身大模型的训练,当前大模型与机器人技术融合的具身智能赛道快速发展,这类细分场景的标注数据集是训练通用具身模型操作能力的核心数据资源,可帮助模型提升家务场景、工业分拣场景下的通用操作准确率。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)