

多模态大模型的商业化落地进程中,垂直场景、非英语语种的标准化评测数据集是核心基础设施类供给。当前全球多模态评测数据集多以英语场景为核心,面向意大利语等小语种、聚焦文本类图像的视觉问答(VQA)评测基准长期处于缺失状态,制约了多模态技术在意大利本地政务服务、文旅数字化、跨境消费等场景的适配迭代。
近日,意大利巴里大学(Università degli Studi di Bari Aldo Moro,简称UNIBA)SWAP研究团队正式发布ETCII(Evaluation of Text-Centric Italian Images)基准数据集,该数据集于2026年5月9日首发于HuggingFace平台,是业内为数不多专门针对意语文本类图像的VQA能力评测基准。SWAP研究组长期深耕语义网技术、多模态信息提取、自然语言处理领域研究,此前已推出多个面向欧洲小语种的语言技术工具与数据集,在区域语言数字化领域具有较高的行业认可度。
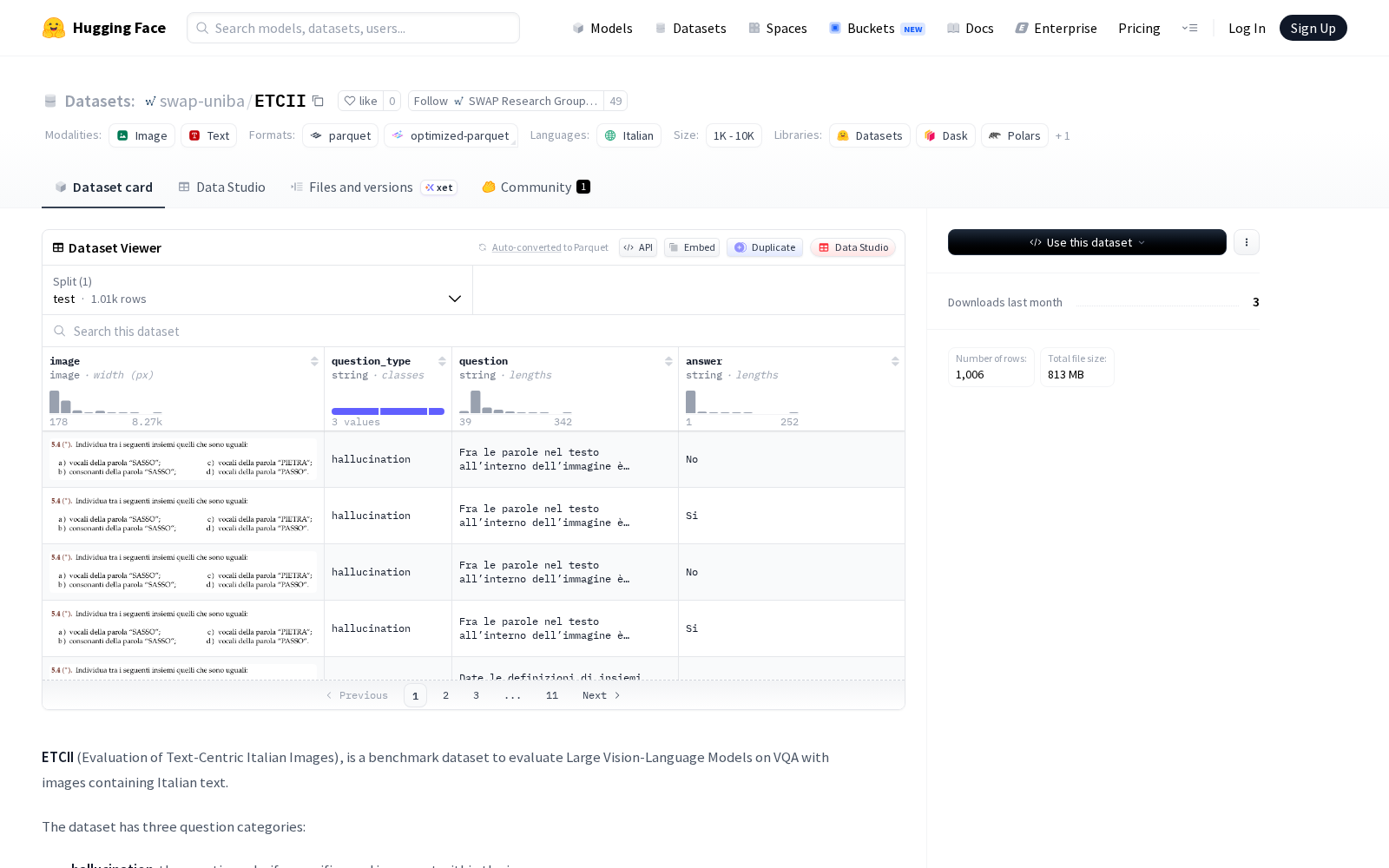
据公开信息显示,ETCII数据集共覆盖107张包含意大利语文本的独特图像,配套1006个标注问答对,总大小约835MB,数据集字段包含图像、问题类型、问题、标准答案四个核心维度,可直接用于大型视觉语言模型的能力评测。本次发布的数据集将评测维度划分为三大类:其一为幻觉类问题,主要考察模型是否能准确识别图像中存在的意大利语词汇,避免编造不存在的文本信息,可针对性检测多模态模型的常见幻觉问题;其二为推理类问题,答案无需调用外部知识库,仅需基于图像中的文本信息完成常识推理即可获得,重点考察模型对文本语义的理解与逻辑推导能力;其三为知识类问题,答案需要结合图像文本信息与通用外部知识获得,考察模型的多模态信息关联与知识调用能力。
从应用场景来看,ETCII数据集可广泛应用于多类意语场景的多模态技术迭代:面向意大利本地政务服务领域,可用于评测多模态模型对意语办事材料、公共标识的自动问答能力,优化政务自助服务终端的交互体验;面向文旅数字化领域,可用于评测模型对意语文物标牌、古籍文本的识别问答能力,支撑智慧导览、古籍数字化产品的功能优化;面向跨境电商领域,可用于评测模型对意语商品包装、说明的信息提取能力,降低面向意大利市场的商品信息自动审核、用户咨询自动应答的研发成本。
作为小语种垂直多模态评测数据的重要补充,ETCII数据集的发布不仅完善了全球多模态评测基准的语种覆盖体系,也为其他小语种的文本类图像评测数据集建设提供了可参考的设计范式,对推动多模态大模型的全球化落地、完善全球多语言数据要素基础设施具有积极意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)