

随着AI代理、多模态大模型技术的快速落地,面向真实场景的工具调用、任务执行能力正在成为行业评价模型商用价值的核心指标,但长期以来,业内缺乏覆盖真实web环境、统一标准的评估基准,不同研究团队、厂商的AI代理测试结果难以横向对比,也制约了模型的迭代效率。2026年5月10日,TIGER-Lab正式在HuggingFace首发开源ClawBench基准测试数据集,瞄准AI网络代理能力评估需求,为行业提供标准化的测试标尺。
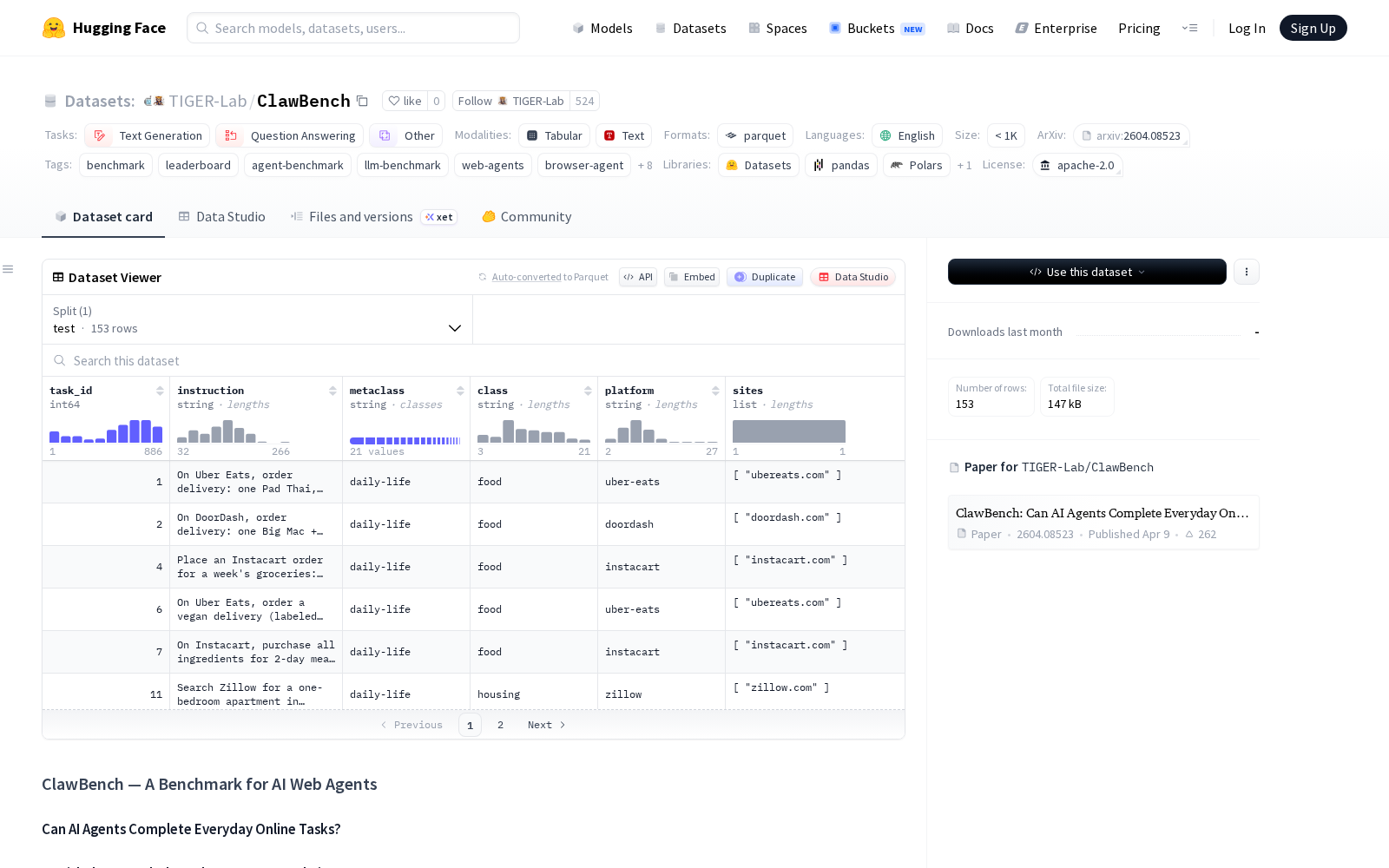
据介绍,ClawBench是专门面向真实网站日常在线任务的AI代理开源评估数据集,核心目标是测试AI代理在无预设置的真实web环境中,完成各类高频在线操作的能力,覆盖场景包括机票酒店预订、生鲜杂货采购、求职申请提交、公共服务办理等多类用户日常高频使用的互联网服务。本次公开的数据集包含两个版本:V1版本覆盖144个主流公开网站、合计153项标准化测试任务;V2版本在V1的基础上新增130项全新测试任务,进一步覆盖了垂直类平台、To B服务平台等此前较少被纳入评估体系的场景。
相较于传统模拟环境下的评估数据集,ClawBench的核心优势在于全链路的行为数据采集:每一项测试任务的运行过程中,都会同步捕获五层行为数据,包括完整会话回放、全流程屏幕截图、全链路HTTP流量数据、AI代理的推理过程痕迹、浏览器端的操作事件记录,同时配套采集了对应任务的人类真实操作数据集作为对照基准。数据集的结构化字段覆盖任务ID、操作指令、任务元类别、所属平台等核心信息,同时提供了额外的共享文件与任务特定上下文说明,大幅降低了研发团队的接入使用门槛。目前ClawBench可广泛适配文本生成、知识问答、工具调用等各类AI代理相关任务的评估需求,原生支持多模态能力的统一测试。
从行业应用价值来看,ClawBench的落地将为多个领域的技术迭代提供支撑:在AI代理研发领域,研发团队可通过该数据集统一测试代理的任务完成率、操作合规性、响应效率等核心指标,实现不同技术路线的横向对比;在多模态大模型迭代领域,配套的屏幕截图、操作轨迹等多模态数据,可用于测试模型对视觉信息、文本指令、交互动作的协同处理能力,推动多模态模型从「感知」向「执行」的能力升级;此外,该数据集还可用于RPA(机器人流程自动化)工具的能力测试、AI操作的人类对齐研究等多个方向。
作为AI训练测试类数据要素的典型代表,ClawBench的发布也填补了AI代理真实场景公开评估基准的供给空白,对推动AI代理产业的标准化建设、加速大模型技术的商用落地具有重要意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)