

随着生成式AI技术在文创、电商、影视、工业设计等领域的加速落地,高分辨率可控图像编辑已经成为行业刚需。但长期以来,该领域面临训练数据供给不足的痛点:现有公开数据集普遍存在样本分辨率偏低、编辑场景覆盖有限、标注精度参差不齐等问题,直接导致扩散模型在执行局部编辑指令时,容易出现非目标区域被意外修改的「编辑泄漏」问题,编辑效果与用户指令的匹配度难以满足商用要求,成为制约可控图像生成技术规模化落地的核心瓶颈。
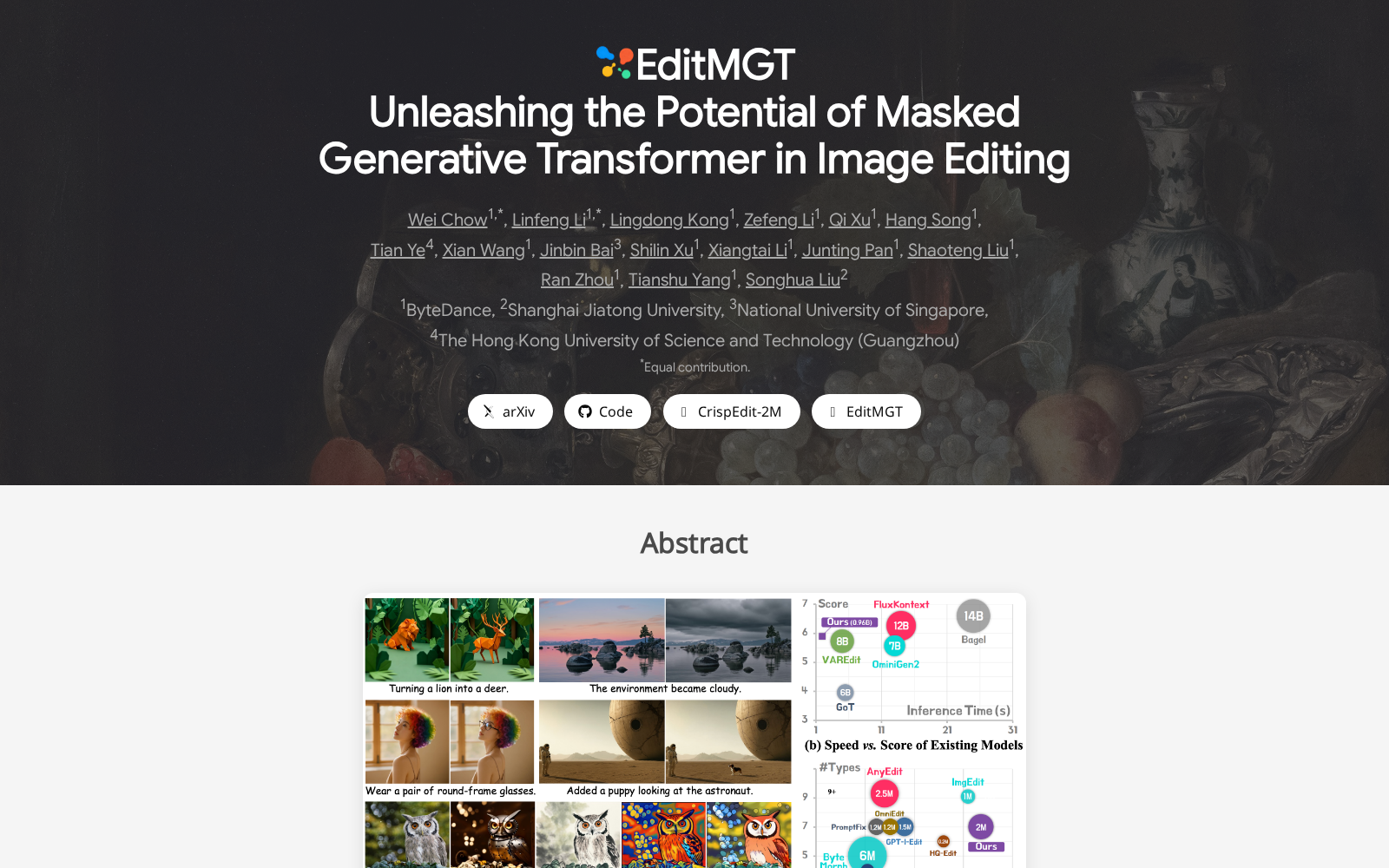
2026年5月12日,字节跳动联合相关机构在arXiv平台正式发布CrispEdit-2M高分辨率图像编辑数据集,正是瞄准这一行业痛点打造的基础数据资产。据介绍,该数据集专为基于掩码生成变换器的图像编辑模型提供训练支持,整体规模达200万份高质量标注样本,所有图像分辨率均不低于1024像素,覆盖对象转换、风格迁移等7类主流图像编辑场景,所有数据均经过多轮自动化校验与人工过滤,确保标注内容的精准性与样本的多样性。其构建过程整合了多源图像资源与标准化文本编辑指令,从数据源头优化训练样本的指令匹配度,针对性解决扩散模型的编辑泄漏问题,为局部化、可控的图像生成与编辑技术迭代提供核心数据底座。
从应用场景来看,依托该数据集训练的图像编辑模型,可在多个领域实现商业化落地:在电商场景中,商家可通过文本指令快速修改商品的颜色、材质、摆放场景,无需专业设计师逐张修图,大幅提升商品展示内容的生产效率;在影视后期制作领域,可实现画面局部特效、人物造型的精准调整,降低后期制作的时间与人力成本;在工业设计场景中,设计师可通过指令快速修改产品原型的局部结构、外观风格,加速产品方案的迭代效率;在文创内容创作领域,画师可借助可控编辑能力快速调整插画的局部细节、整体风格,减少重复性劳动投入。
作为AI产业的核心生产要素,高质量垂类训练数据集的供给能力,直接决定了AIGC技术的落地上限。本次字节跳动发布的CrispEdit-2M数据集,填补了高分辨率可控图像编辑领域的优质训练数据缺口,不仅为相关技术的研发提供了核心支撑,也为国内AI基础数据资产的建设、数据要素在AIGC赛道的价值释放提供了典型参考。
详情页内容:



_1769672084863.jpg)