

作为全球顶尖的计算机科学与应用数学研究机构,法国国家信息与自动化研究所(INRIA)长期在机器学习、数据科学领域产出前沿成果,其发布的各类基准数据集也常成为全球技术研究者的核心参考工具。近年来,随着各行业数字化转型的深化,表格作为政务、金融、零售等领域最通用的数据承载形式之一,混合数值与字符串特征的表格智能处理需求快速攀升,但此前行业内的主流基准数据集普遍侧重数值型、固定分类特征的建模,大多忽略了真实场景中大量存在的高异质性字符串特征,导致相关算法的研发、效果评估缺乏统一的参照标准,成为制约表格学习技术落地的核心瓶颈之一。
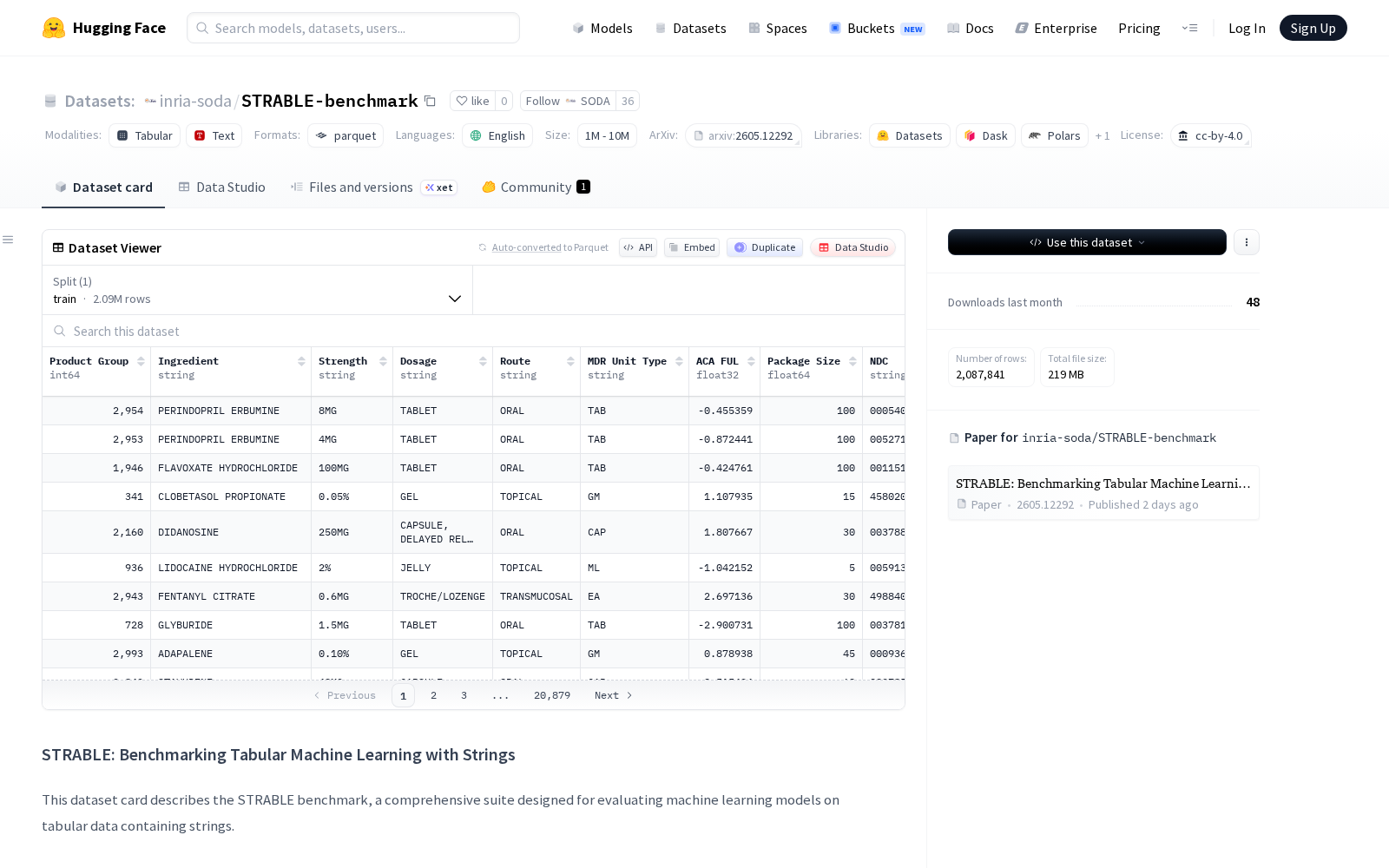
针对这一行业空白,INRIA SODA团队联合相关机构正式发布STRABLE基准数据集,该成果已于2026年5月12日首发于预印本平台arXiv。据官方介绍,STRABLE数据集共纳入108个来自真实场景的表格样本,覆盖三类主流监督学习任务,包含13个二分类任务、19个多分类任务和76个回归任务,数据集规模中位数为7.7K行、18列,其中的字符串特征覆盖名称、结构化代码、自由文本等多种真实场景常见类型。为最大化还原真实业务中的数据特性,研发团队从33个不同来源收集原始数据后仅进行了最小化预处理,完整保留了字符串的原始异质性,避免了过度清洗带来的特征失真问题,确保数据集的测试结果具备真实场景参考价值。
该数据集的核心定位是为混合数值与字符串特征的表格学习算法提供统一的性能评估基准,解决了传统基准普遍忽略高基数语义字符串的局限性,可为相关领域研发端到端学习架构、模块化技术流水线提供标准化的实证基础。从产业应用角度来看,这类混合特征表格学习技术可广泛适配多个垂直场景的需求:比如金融风控领域,包含客户身份信息、交易备注、机构代码等字符串特征和交易金额、征信评分等数值特征的风控模型效果验证;政务服务领域,包含办事地址、统一社会信用代码、事项名称等字符串特征和办理时长、办结率等数值特征的效能分析模型研发;零售行业,包含商品名称、用户地址、评价片段等字符串特征和消费金额、复购次数等数值特征的用户画像建模等,STRABLE数据集的出现将为上述场景的技术选型、效果验证提供统一标尺,加速相关技术的落地迭代,推动表格智能处理技术在各产业数字化场景中的普及。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)