

随着生成式语音技术的快速迭代,语音合成、个性化语音克隆、语音大模型等赛道的创新需求持续攀升,而高质量、预处理完成的标准化训练数据,始终是制约中小团队快速落地产品的核心门槛之一。原始语音数据集的文本转录普遍需要开发者自行完成分词、格式对齐等预处理工作,不同分词方案的兼容性差异也会提升模型迁移与效果对比的成本,在此背景下,Trelis本次发布的libritts-bpe-tokens数据集,为行业提供了开箱即用的标准化文本token解决方案。
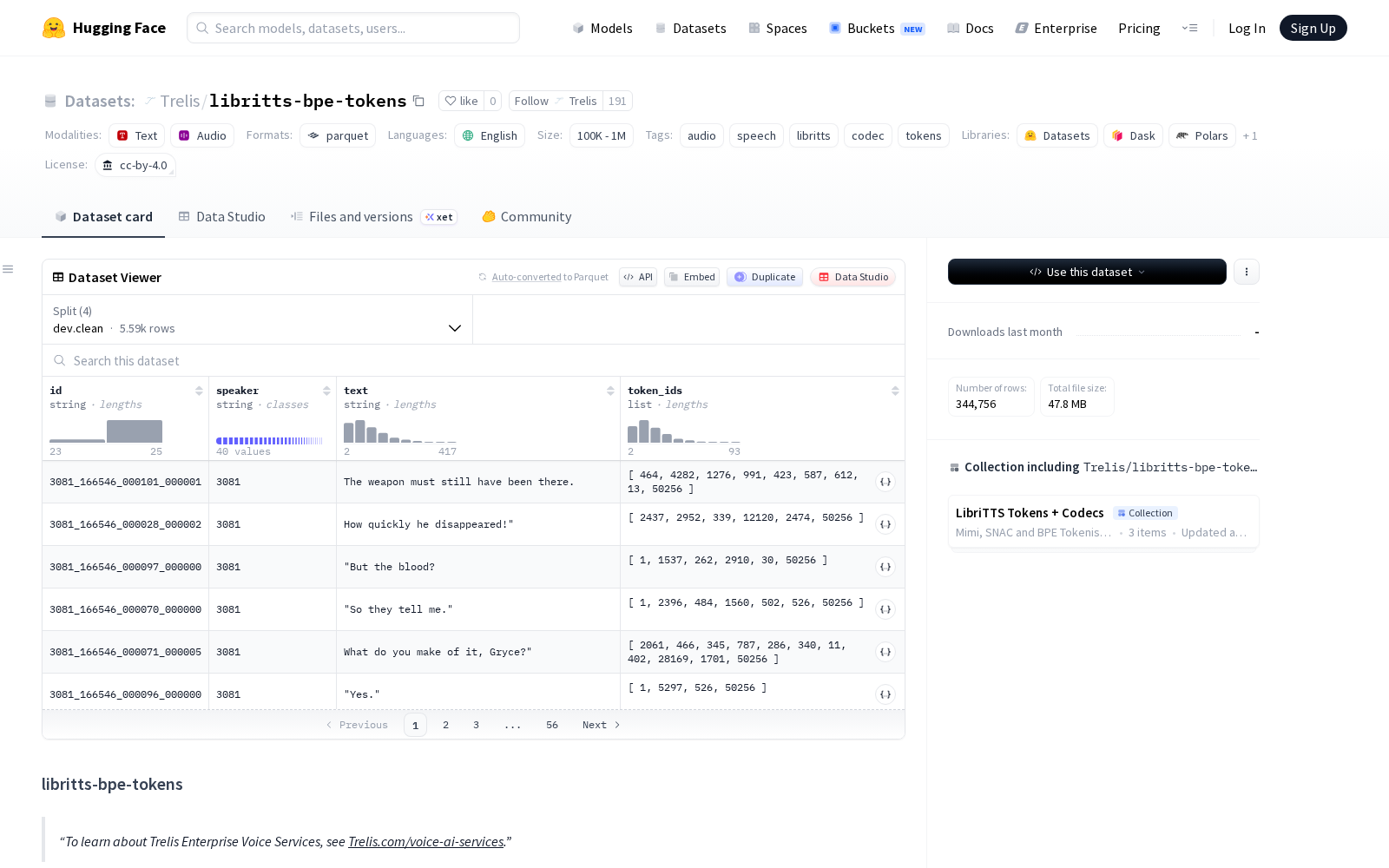
据了解,libritts-bpe-tokens是基于LibriTTS-R语音数据集打造的文本token表示数据集,研发团队采用GPT-2 BPE分词器对LibriTTS-R的标准化文本转录内容进行统一处理,为每个话语生成对应的token ID序列,并在序列末尾添加了ID为50256的EOS token,词汇表大小为50257,与当前主流大语言模型的分词体系高度兼容。该数据集完全遵循原始LibriTTS-R的分割结构,覆盖约538小时音频对应的文本内容,分为四个标准子集:train.clean.100(约32k个话语,53小时)、train.clean.360(约112k个话语,218小时)、train.other.500(约250k个话语,258小时)和dev.clean(约5.6k个话语,9小时),且训练集与开发集的说话人完全无重叠,可有效避免模型训练过程中的数据泄露问题,提升模型的泛化能力。数据集的每一行代表一个话语,包含四个字段:`id`(原始LibriTTS的话语标识符,格式为speaker_chapter_segment)、`speaker`(说话人ID)、`text`(原始的标准化文本)和`token_ids`(GPT-2 BPE token ID列表,类型为uint32),方便开发者直接调用适配不同训练需求。
目前该数据集可广泛应用于各类需要预训练文本token表示的语音处理任务:在语音合成场景中,开发者可直接调用token序列完成文本到声学特征的映射训练,无需额外处理文本分词环节;在语音识别场景中,统一的token体系可降低解码环节的适配成本,提升识别结果的稳定性;除此之外,该数据集还可用于语音语言模型预训练、跨模态语音-文本对齐任务、个性化语音克隆的文本预处理、低资源语音模型微调等多个方向,为不同细分赛道的研发工作提供标准化的数据支撑。作为Trelis推出的同源token化数据集系列之一,该数据集采用GPT-2 BPE分词方案,官方还同步提供了采用其他分词方案的变体数据集,可满足不同技术栈开发者的差异化需求。
该数据集的原始数据来源于已过滤的parler-tts/libritts_r_filtered数据集,原始音频采样率为24kHz,部分配套数据集的音频经过了重采样或截断(超过20秒的话语音频被截断,但文本保留完整),可适配不同长度的语音训练任务。授权方面,数据集本身遵循CC-BY-4.0许可证,与原始LibriTTS-R的授权规则一致,所使用的GPT-2分词器采用MIT许可证,两类授权均对商业应用友好,开发者可免费用于非商业及合规的商业研发场景。
在数据要素市场化建设持续推进的背景下,垂直领域的预处理数据集已成为AI基础设施的重要组成部分,本次libritts-bpe-tokens数据集的发布,填补了LibriTTS-R生态下标准化BPE分词数据集的空白,进一步降低了语音AI领域的研发门槛,对推动生成式语音技术的普惠落地具有积极意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)