

随着生成式AI在代码开发、智能代理领域的落地加速,基准数据集的可信度直接决定了模型性能评估的准确性与训练效果的实用性,但当前不少专用测试集普遍存在无效任务占比高、评估结果虚高的痛点,难以支撑产业级应用的研发需求。作为全球范围内极具影响力的开源AI数据集非营利组织,LAION eV此前推出的LAION-5B等多模态数据集曾作为Stable Diffusion等主流生成式AI模型的核心训练基座,在开源AI数据治理领域拥有深厚的技术积累与行业认可度。
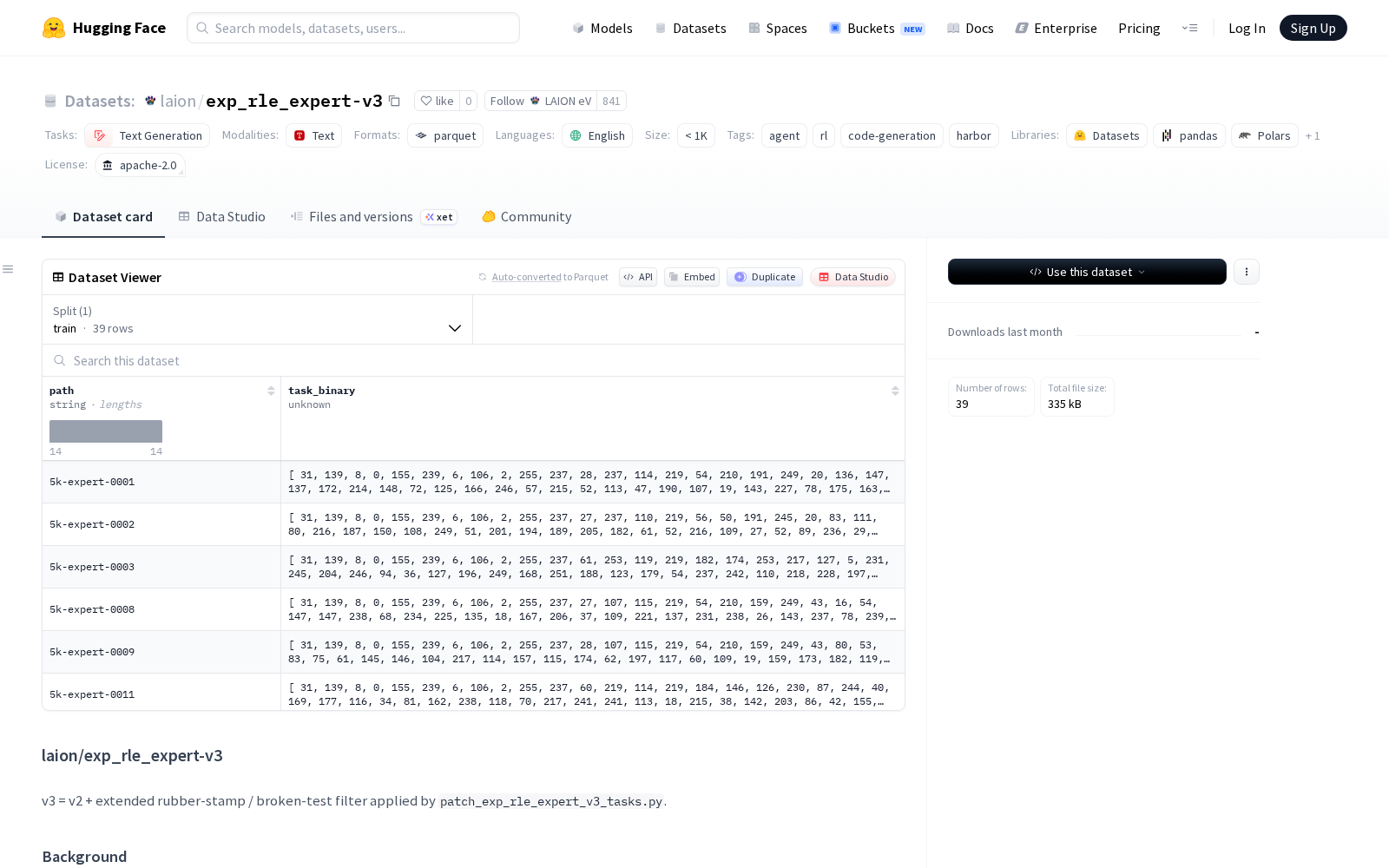
LAION eV本次发布的数据集exp_rle_expert-v3,是exp_rle_expert-v2的扩展过滤版本,定位为代码生成、强化学习任务专用的高纯度基准数据集,首发上线于HuggingFace平台。该数据集的迭代核心目标是通过严格的过滤规则移除无效或低质量的测试任务,从源头解决基准评估结果失真的行业痛点。
背景信息显示,此前的v2版本共包含730个测试任务,但其中存在大量“橡胶图章”测试(即无论代理行为如何都能通过的测试),直接导致模型在该数据集上的解决率虚高,无法反映真实的任务解决能力,难以支撑实际研发需求。为解决这一问题,v3版本应用了10条过滤规则(R1-R10),包括移除非标准库导入、过时代码、缺失系统二进制文件、未定义pytest夹具、无测试函数、平凡断言以及未引用代理解决方案的任务。经过多轮清洗过滤,数据集从730个任务缩减至39个任务,保留率仅为5.3%。官方披露的质量检测数据显示,在一个203个轨迹的质量控制样本中,过滤后任务集的解决率为8.3%,较v2版本的虚高解决率大幅下降,证明过滤规则有效去除了数据集中的污染项,任务的有效性和实用性得到显著提升。
从应用方向来看,该数据集可广泛应用于多个AI研发场景:在代码生成领域,可作为大语言模型代码生成能力的基准评估工具,避免模型通过“刷分”方式获得虚高性能评分,帮助研发团队更精准地判断模型在真实工业场景下的代码编写、调试、优化能力;在强化学习领域,可用于智能代理的训练与效果验证,支撑代码自动开发代理、DevOps智能运维代理、自动漏洞挖掘代理等垂直场景智能体的研发,避免智能代理学习到“钻测试规则漏洞”的投机行为,真正提升任务解决能力;此外,该数据集的标准化任务规则,也可为代码安全检测、代码合规校验等领域的研究提供基础数据参考。该数据集语言为英语,规模较小(少于1K样本),适用于文本生成、代理开发和代码生成研究方向。
当前AI训练与评估数据集作为AI产业的核心基础设施,其质量治理已经成为全球数据要素领域关注的核心议题。此次LAION推出的exp_rle_expert-v3数据集虽然样本规模不大,但其“小而精”的定位填补了代码与强化学习领域高可信度基准数据集的空白,其采用的多维度规则过滤方法,也为行业数据集治理、低质量数据剔除提供了可参考的实践范式,对推动AI技术在软件开发等垂直领域的落地具有重要的参考价值。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)