

随着多模态大模型产业进入落地深水区,视觉语言模型(VLM)的能力边界正从「看得懂」的感知层向「会思考」的推理层延伸,但传统端到端混训模式下,模型往往存在视觉识别能力强、逻辑推理能力弱的偏科问题,将感知与推理环节解耦的分阶段训练,也成为当下VLM性能提升的主流技术路径之一。UCSC-VLAA本次发布的VLM-CapCurriculum-TextReasoning-Data(简称D_text),正是配套其发表于ICML 2026的论文《From Seeing to Thinking: Decoupling Perception and Reasoning Improves Post-Training of Vision-Language Models》的核心支撑数据集,专门用于VLM分阶段后训练方法的第二阶段,核心作用是在第一阶段的感知能力训练与第三阶段的视觉推理强化学习(RLVR)训练之间,搭建文本推理能力巩固的衔接层,避免模型直接切入多模态推理任务时出现逻辑能力断层。
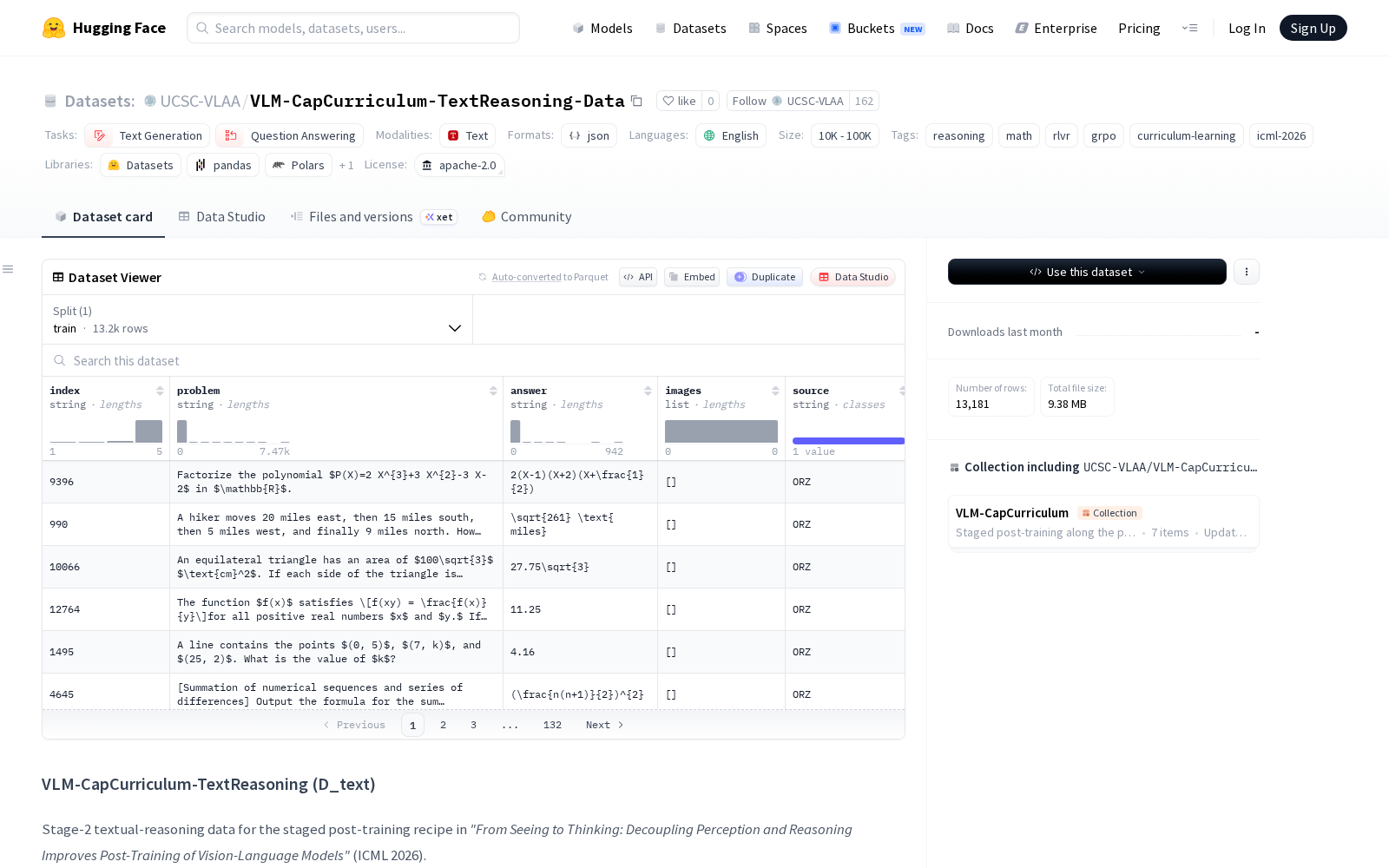
该数据集从公开ORZ-Math-13k集合中精选而出,全部为纯文本形态的高难度数学问题,总训练样本量达13181条,以JSONL格式开放下载。每条样本包含索引、问题、答案、空图像列表、来源、基础模型Qwen3-VL-8B-Instruct的16次预测结果、对应每次预测的正确性标签,以及表征样本难度的通过率指标——该指标为正确性标签的平均值,可直接用于课程式学习实验,支持研发团队按照难度梯度排序训练数据,实现模型能力的渐进式提升,大幅降低训练过程中的能力震荡风险。
目前该数据集可广泛适用于文本生成、智能问答等任务,尤其聚焦数学推理场景:除了作为VLM分阶段训练的核心支撑数据外,也可用于纯文本大模型的数学推理能力微调、多模态模型推理能力的基准评测、强化学习类训练的正负样本标注素材,后续结合多模态标注数据还可拓展至多模态解题、工业图纸逻辑校验、科研文献公式推导等落地场景。开发者可直接通过Hugging Face datasets库加载该数据集,也可集成到EasyR1训练框架中快速使用。数据集采用Apache-2.0开源许可证,使用者仅需引用原始ORZ-Math-13k集合及对应论文即可合规使用,大幅降低了研发团队的数据集采购与合规成本。
查看VLM-CapCurriculum-TextReasoning-Data
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)