

随着多模态大模型与语音交互技术的快速落地,离散音频Token作为连接连续语音信号与大语言模型的核心中间载体,已成为语音AI研发的核心基础资源。此前多数研发团队需要自行完成原始音频的编码、Token化处理,不仅耗费大量算力与时间成本,不同编码标准的差异也会导致模型复用性降低,行业对标准化、预处理完成的高质量音频Token数据集的需求持续攀升。
日前,AI数据集服务商Trelis正式发布libritts-mimi-tokens音频Token数据集,该数据集于2026年5月15日率先上线HuggingFace,是目前行业内为数不多基于成熟RVQ编解码器预处理完成的开源语音Token数据集。
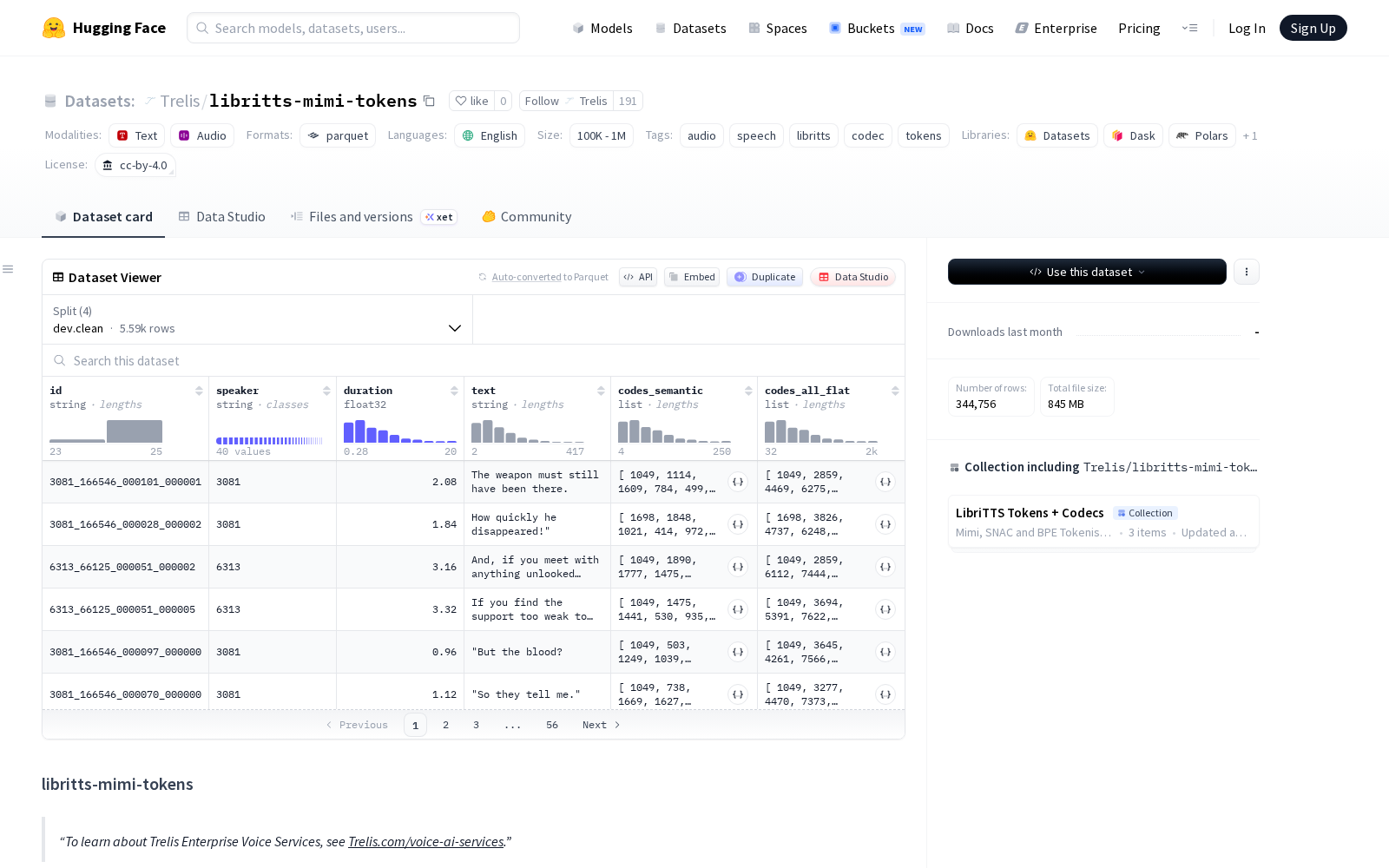
据介绍,libritts-mimi-tokens基于开源高质量朗读语音库LibriTTS-R构建,采用kyutai开源的mimi RVQ(残差矢量量化)神经编解码器完成原始音频编码,该编解码器包含8个独立码本、每个码本对应2048个条目,是当前神经音频压缩与Token化的主流技术方案。本次发布的数据集生成了两种不同时间分辨率的离散Token序列,可适配不同研发场景需求:1) codes_semantic:仅保留第0码本的语义Token序列,该码本基于WavLM蒸馏训练、具备优秀的语音内容对齐能力,采样率为12.5帧/秒,词汇表大小为2048,适合偏语义理解类的语音模型训练;2) codes_all_flat:将8个码本的Token按帧交错排列并完成偏移映射的扁平化序列,采样率为100帧/秒,偏移后有效词汇表大小为16384,可直接被普通扁平语言模型识别不同码本的信号差异,更适合偏语音生成、编解码优化类的研发任务。
该数据集完全遵循LibriTTS-R过滤后的划分规则,包含4个无说话人重叠的独立子集,分别为`train.clean.100`(约3.2万条语句,总时长53小时)、`train.clean.360`(约11.2万条语句,总时长218小时)、`train.other.500`(约25万条语句,总时长258小时)和`dev.clean`(约5600条语句,总时长9小时),累计总时长约538小时。每条数据样本对应一条独立话语,包含唯一标识符id、说话人ID、音频时长、归一化文本以及上述两类Token序列共5个字段。预处理环节中,原始24kHz采样率的音频直接用于Mimi编码,仅对时长超过20秒的话语做音频截断处理,对应文本完整保留。数据集采用CC-BY-4.0许可协议,商业使用友好。
从应用价值来看,该数据集除了可直接用于语音语言建模、神经编解码器建模、语音合成等基础语音AI研发任务外,还可支撑语音克隆、多模态大模型语音输入输出模块训练、低资源语种语音识别、实时端侧语音交互模型优化等多个前沿方向的研发,可帮助研发团队省去音频Token化的预处理环节,大幅缩短研发周期、降低算力成本,对推动语音交互技术在智能家居、数字人、无障碍服务等场景的落地具有积极作用。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)