

随着代码大模型技术的快速迭代,AI编程、程序合成、自动化测试等领域的技术落地速度不断加快,行业对高可信度、高可运行性的统一基准评估数据集的需求持续攀升。作为全球知名的开源AI数据组织,LAION eV曾凭借LAION-5B等大规模多模态数据集成为文生图技术爆发的核心数据支撑,本次其布局代码类垂直数据集领域,正是回应产业端对高质量代码基准数据的迫切需求。
LAION eV本次发布的exp_rle_github_issue-v3数据集,是前序版本laion/exp_rle_github_issue-v2的深度过滤迭代版,专门针对代码类文本生成任务设计,核心优化方向为提升任务的可运行性与模型解决率的参考价值。该数据集共包含264个经过多轮校验的编程任务实例,筛选自v2版本的739个原始任务,保留率为35.7%,每个任务包含path(字符串类型)和task_binary(gzipped压缩的任务目录)两个字段,可直接对接主流代码大模型的评估测试框架。
本次过滤流程基于对v2版本数据集的200次重复试验评估,共识别并移除了五类无法正常运行的无效任务:其中缺失测试夹具的任务共311个、存在损坏的子属性引用问题的任务共116个、存在从tests模块导入问题的任务共36个、存在模块级importorskip调用的任务共9个、存在模块级环境/路径操作的任务共2个。经过本轮清洗优化后,数据集的平均模型解决率从原版本的7.0%提升至20.3%,提升幅度达3倍,大幅降低了无效任务对评估结果的干扰,评估数据的可信度与产业参考价值显著提升。
从应用场景来看,该数据集可广泛应用于多个代码AI领域的研究与产业落地:在代码大模型研发端,厂商可依托该数据集搭建统一的代码生成能力评估体系,实现不同模型能力的横向对标,减少自研测试用例的研发成本;在程序合成领域,科研团队与技术厂商可将其作为标准验证集,测试AI对复杂编程任务的拆解、生成与调试能力;在企业DevOps场景中,该数据集可作为自动化测试用例生成工具的基准校验集,帮助企业提升测试环节的智能化水平,降低研发流程中的测试人力投入。
Dataset card内容:
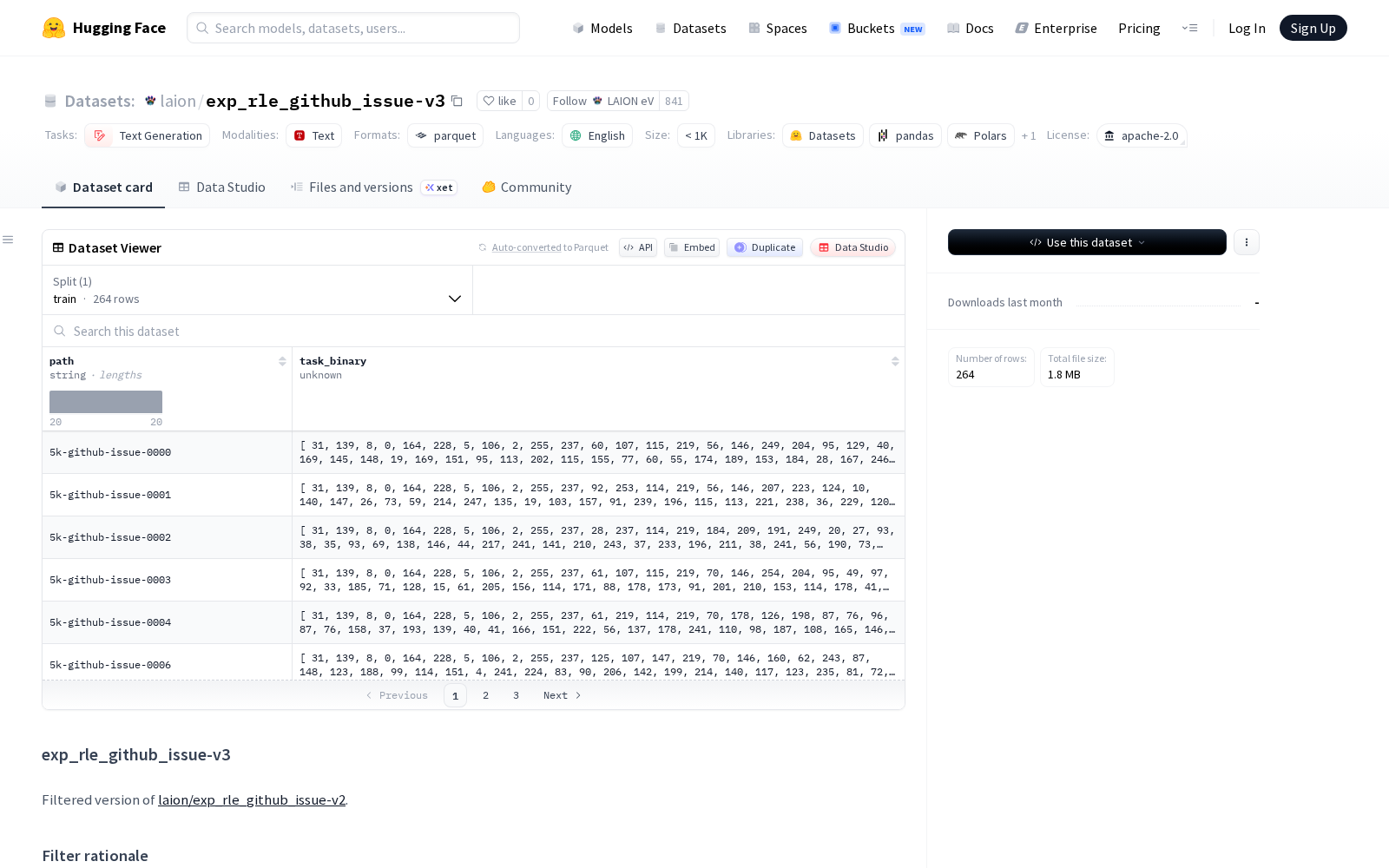
Files and versions内容:
当前全球数据要素市场建设正不断向垂直领域深化,AI训练与基准数据集作为人工智能产业的核心生产要素,其质量直接决定了技术迭代的效率与落地可行性。本次LAION eV发布的高可信度代码基准数据集,不仅为全球代码AI领域的研发提供了统一的评估标尺,也为国内垂直领域数据集的打磨迭代提供了参考样本,将进一步推动AI编程技术的产业落地,助力数字经济背景下的全行业研发效率提升。



_1769672084863.jpg)