

作为全球知名的开源AI数据组织,LAION eV此前因构建Stable Diffusion核心训练数据集LAION-5B被行业熟知,长期专注于高质量AI训练数据集的开源共享,是全球AI开源生态的核心贡献方之一。当前,以强化学习驱动的代码智能体正成为AI编程领域的核心研发方向,无论是企业级DevOps智能化升级,还是通用代码大模型的能力迭代,都依赖高质量的代码任务训练数据集。但过往大量开源代码数据集普遍存在任务不可解、依赖缺失、规则不清晰等问题,不仅会造成训练阶段的算力浪费,还会导致模型生成的代码在真实场景下可用性不足,成为制约代码类AI能力落地的核心痛点之一。
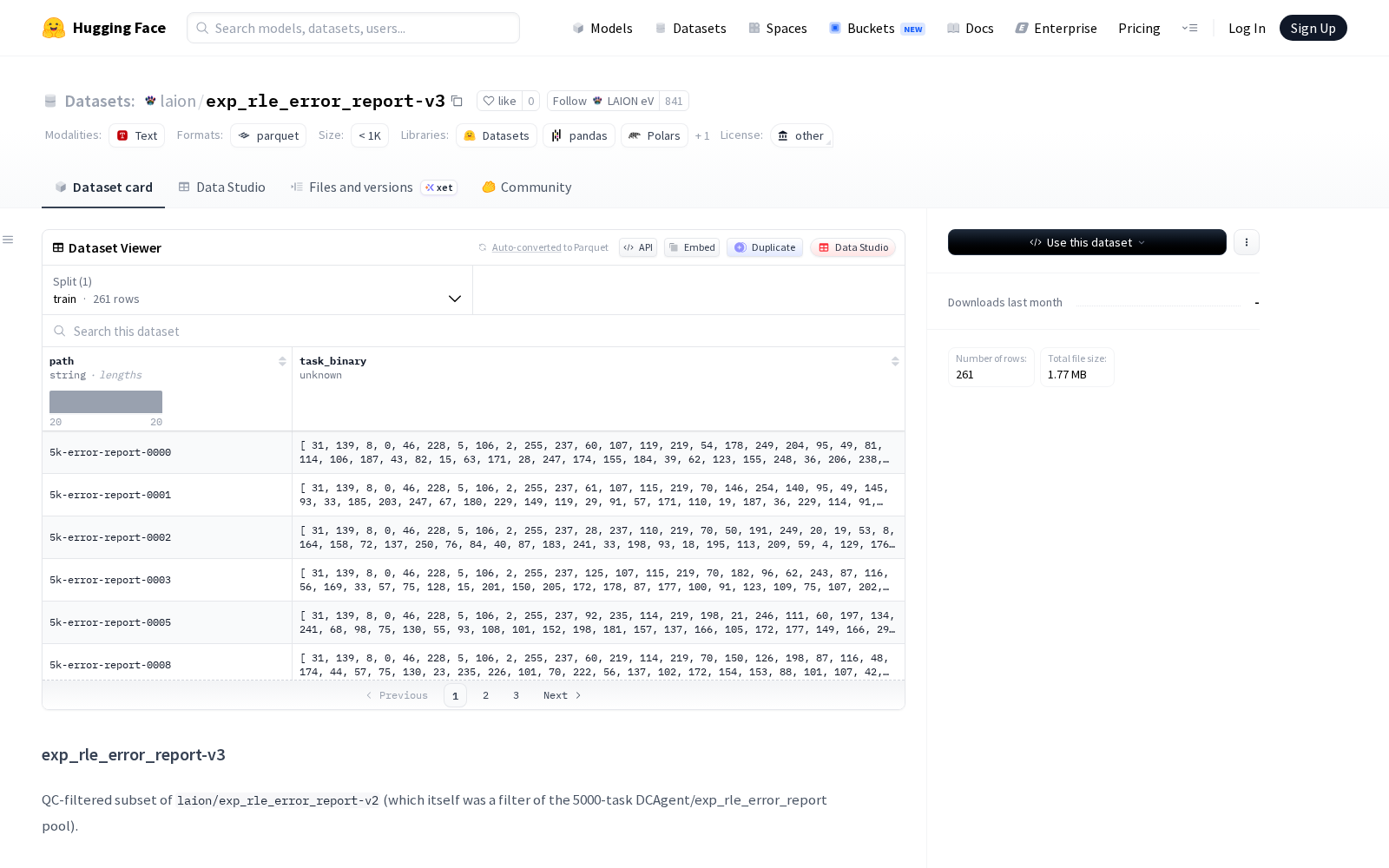
LAION eV本次发布的exp_rle_error_report-v3,正是针对上述行业痛点推出的高质量代码任务数据集,旨在为强化学习(RL)智能体训练提供更高质量、更可解决的任务环境。该数据集源于包含5000个任务的DCAgent/exp_rle_error_report池,是其前身laion/exp_rle_error_report-v2的进一步优化子集。
创建v3版本的直接动机源于对v2版本的评估反馈:尽管基础设施运行正常,但v2数据集的任务解决率极低(仅5.0%)。深入分析发现,v1版本的过滤器未能有效排除三类结构性不可解决任务:1) 测试文件中引用了未提供的pytest夹具;2) 导入了已弃用的点分式子模块;3) 其他系统性错误(如使用已弃用的API或依赖缺失的系统二进制文件)。
为此,v3版本应用了一套包含七条规则(R1-R7)的增强过滤器,专门针对上述问题进行过滤,例如阻止特定已弃用模块的导入、检测缺失的pytest夹具定义、以及扫描对沙箱环境中不存在的系统命令的调用。经过筛选,数据集规模从v2的759个任务减少到261个任务。验证表明,该过滤器在100%保留所有可解决任务的同时,移除了73.7%的失败任务,预计将任务解决率从v2的5.0%提升至16.7%,提升幅度达3.33倍。
数据集以单个Parquet文件(tasks.parquet)的形式提供,包含两个字段:path(任务标识符)和task_binary(包含任务文件夹内容,如元数据、指令、配置、测试代码和Dockerfile的gzip压缩tar包)。
从应用场景来看,exp_rle_error_report-v3数据集可覆盖多个代码AI研发场景:一是强化学习代码生成模型的微调训练,帮助智能体快速学会处理依赖适配、弃用API规避、测试框架适配等真实代码场景问题;二是代码任务质量评估的基准工具,可为各类代码大模型、AI编程助手的能力测评提供统一、高可信度的测试集;三是企业内部代码自动化校验工具的训练样本,帮助企业搭建适配自身技术栈的代码质量自动检测体系。相关研发方基于该数据集开展训练,可大幅降低无效数据带来的算力损耗,缩短代码智能体的研发周期。
该数据集的发布,也为垂直领域训练数据集的迭代优化提供了参考范式:通过针对性的规则过滤剔除无效样本,用更小的数据集规模实现更高的训练效率,符合当前AI训练数据从「规模化」向「高质量化」演进的行业趋势,对代码类AI生态的发展具有重要的支撑作用。目前该数据集已首发上线HuggingFace,全球开发者可免费获取使用。
查看exp_rle_error_report-v3
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)