

当前全球软件开发正朝着DevOps一体化、AI辅助编程的方向快速演进,依赖管理混乱、静态代码分析准确率不足、自动化测试用例有效性低等问题,已经成为制约企业研发效率提升的核心痛点,而垂直场景下的高质量代码数据集,是支撑相关工具迭代、技术落地的核心基础。作为全球领先的开源AI数据集建设机构,LAION eV曾推出支撑Stable Diffusion等跨世代生成式AI产品训练的大规模公开数据集,在多模态、代码类数据集的构建、治理领域拥有广泛的行业认可度。
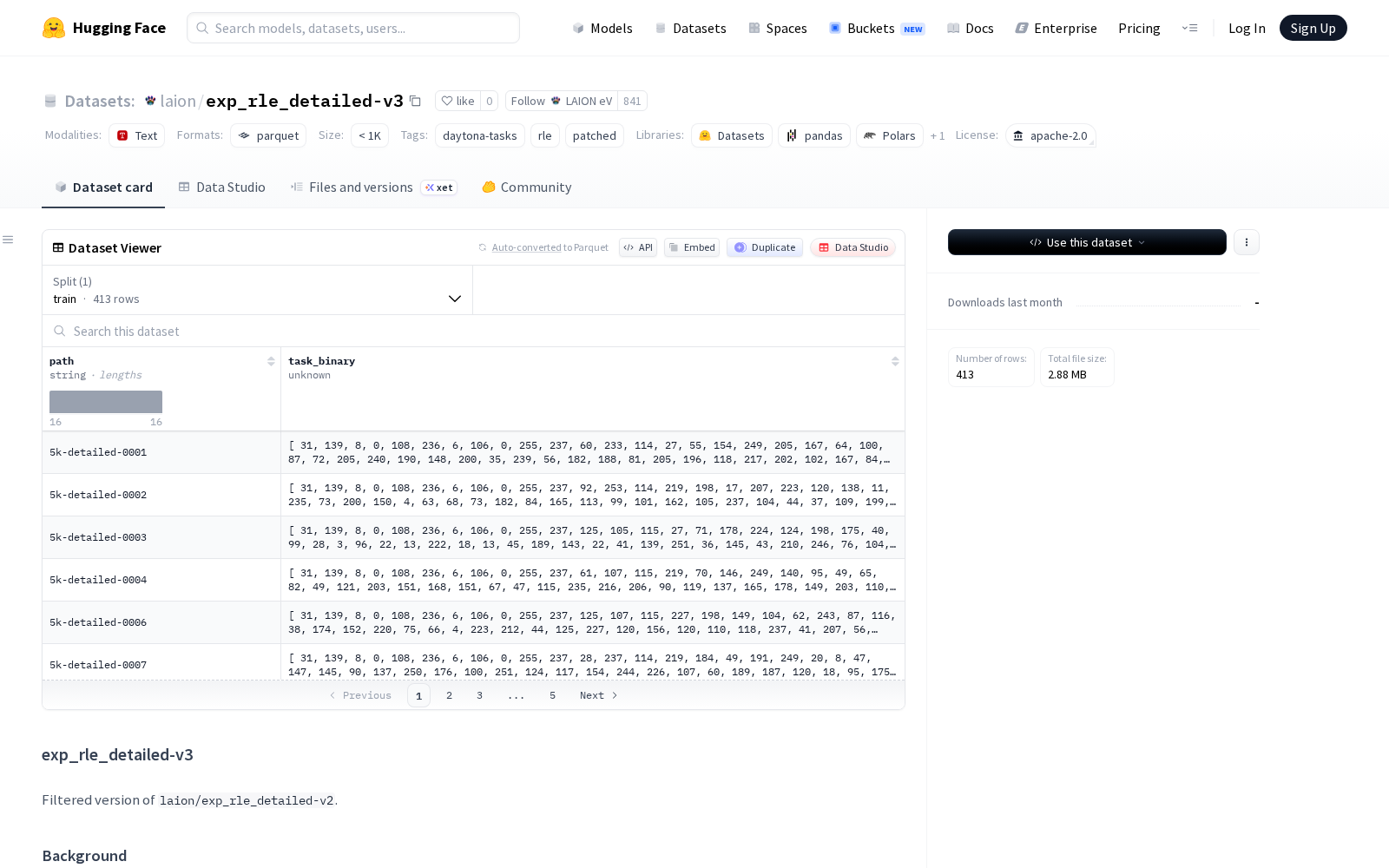
本次LAION eV发布的exp_rle_detailed-v3数据集,是laion/exp_rle_detailed-v2的过滤优化版本,专门针对代码执行环境中的依赖导入问题设计,通过静态分析技术识别并移除了可能导致ImportError、ModuleNotFoundError的任务实例,重点解决测试集合阶段的模块导入失败问题,大幅提升数据集的可用性与场景适配性。
该数据集在构建过程中设置了多层过滤机制:一是子模块黑名单规则,覆盖pandas.util.testing、sklearn.utils.testing等常用工具的内部测试路径,避免废弃、非公开接口导致的导入错误;二是本地名称导入检查,过滤包含硬编码本地依赖的任务实例,保障数据集在不同环境下的通用性;三是pytest插件标记检测,适配主流测试框架的执行规范;四是importorskip调用验证,识别条件导入场景下的异常逻辑;五是无条件跳过测试的识别,过滤无效测试用例,提升数据集的质量密度。
数据维度来看,原始v2版本共包含773个任务,经过多层过滤后v3版本保留413个有效任务,共丢弃360个无效任务,其中丢弃原因分布为:子模块问题402例、顶级导入问题73例、插件问题25例、importorskip问题17例、测试跳过问题7例。经过实测,该优化后的v3版本能够捕获v2版本中88%的导入错误失败案例,数据质量提升显著。
从应用价值来看,该数据集可广泛适配多个软件开发相关场景:在依赖管理工具研发领域,可作为标准化测试集验证依赖自动解析、版本适配工具的准确率,帮助DevOps团队降低生产环境依赖冲突故障发生率;在静态代码分析领域,可为商用代码检测工具、AI代码辅助模型提供训练与测试数据源,提升导入错误识别的准确率,减少代码提交后的测试返工成本;在自动化测试生成场景,可支撑AI测试生成工具的训练,避免生成无法执行的无效测试用例,提升自动化测试的通过率;在代码大模型评估领域,可作为标准化基准数据集,更精准地衡量大模型生成可执行代码的实际能力,而非仅评估语法正确性。
该数据集的推出,也填补了代码类数据集在依赖管理、静态代码分析细分场景的高质量供给空白,对于推动数据要素在软件开发垂直领域的落地应用,助力DevOps产业智能化升级具有重要意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)