

作为数字医疗赛道的核心发展方向,医疗AI尤其是大模型驱动的临床辅助工具近年迎来爆发式增长,但长期以来,不同技术团队的模型性能评估缺乏统一的基准框架,测试数据集、任务设置、评估维度的差异导致不同模型之间很难实现客观横向对标,这也成为医疗AI从实验室走向临床落地的核心阻碍之一。在此背景下,UCSC-VLAA于2026年5月16日在HuggingFace平台首发开源的ClinSeek-Evaluation-Results数据集,正是瞄准医疗AI基准测试、电子健康记录(EHR)评估的标准化需求推出的行业公共资源。
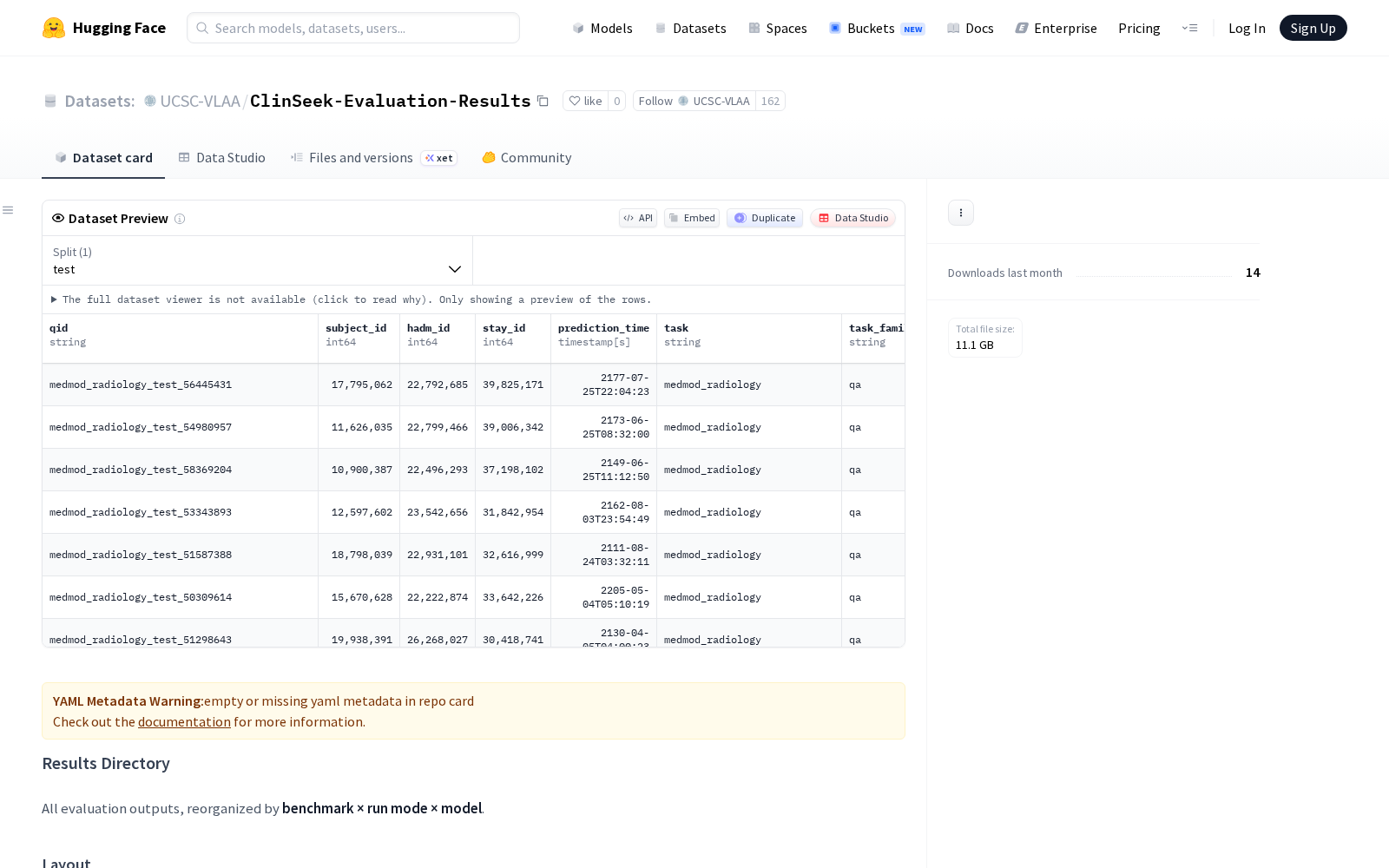
据数据集官方说明,ClinSeek-Evaluation-Results搭建了系统化的医疗AI基准测试评估结果存储与整理目录结构,共覆盖三类主流医疗AI测试场景的基准输出:其一为面向文本型电子健康记录的EHR-Bench基准,包含1800行标注数据与45个细分任务,支持单次(oneshot)推理和多轮智能体(agentic)两种运行模式,可用于测试大模型对文本病历的语义理解、诊断辅助建议生成、治疗方案合理性校验等临床NLP任务性能;其二为AgentEHR-Bench基准,基于全球医疗AI领域应用最广泛的公开重症监护数据集MIMIC构建,包含600行数据与6个专项任务,仅支持多轮智能体模式,可用于验证临床辅助智能体连续跟踪患者病程、跨病历信息整合、多轮医患交互模拟等场景的能力;其三为面向多模态电子健康记录的MM Bench基准,包含2703行数据与6个任务,同时支持单次和多轮智能体模式,其中多轮模式需调用影像阅片工具与EHR检索工具,可用于测试多模态大模型融合医学影像、文本病历信息完成综合临床判断的能力。
为了降低跨模型对比的门槛,该数据集的评估结果按照基准类型、运行模式、测试模型三个维度分层组织,核心输出文件为results.jsonl;目录内还对Claude Opus、Qwen3-VL等当前主流商用、开源大模型完成了标准化命名,同时设置专门的归档目录存放历史或未完成的运行记录,整套结构的核心目标是实现不同大模型在医疗场景下性能表现的系统化管理与公平比较。
对于医疗AI行业而言,该公共数据集的落地一方面可大幅降低科研团队、企业的医疗大模型评估成本,避免重复搭建测试框架的资源浪费;另一方面也为后续医疗AI的性能评估标准统一、临床合规性验证甚至监管准入体系建设提供了可参考的公共工具,有望进一步加速医疗AI的落地普及进程。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)