

随着代码大模型、AI编程助手、自主代码智能体成为人工智能领域的研发热点,编程竞赛、算法求解场景作为验证AI逻辑推理能力、代码生成准确性的核心赛道,长期以来缺乏具备标准化运行环境、自动可验证奖励机制的高质量训练数据集,成为制约相关技术迭代的重要瓶颈。2026年5月16日,曾推出全球规模最大文生图训练数据集LAION-5B的知名开源AI数据集机构LAION eV,正式在HuggingFace平台发布全新数据集nemotron-gym-competitive-coding,瞄准强化学习编程竞赛、算法问题求解场景的核心需求,为行业提供统一的训练与评估底座。
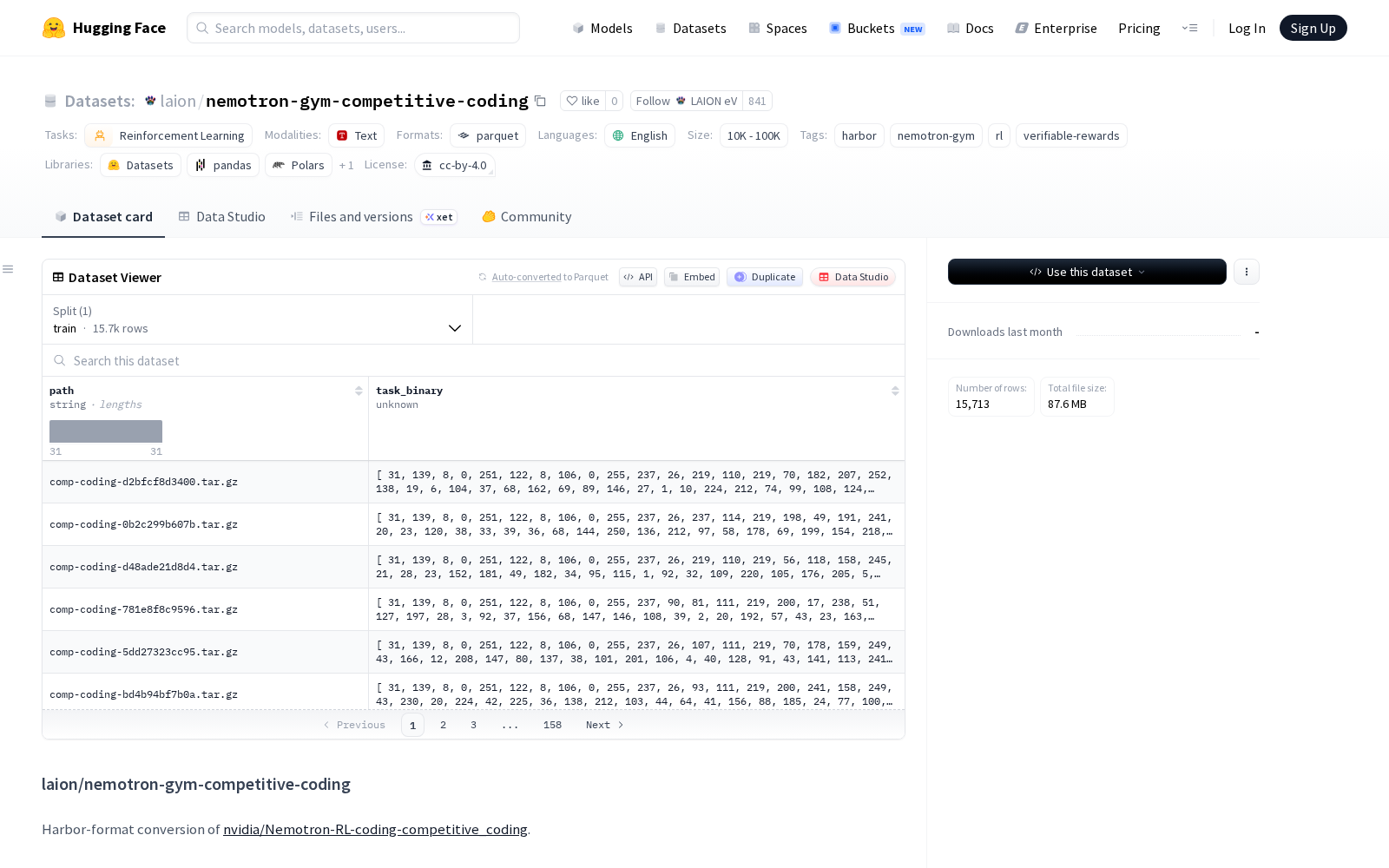
据介绍,laion/nemotron-gym-competitive-coding数据集是nvidia/Nemotron-RL-coding-competitive_coding数据集的Harbor格式转换版本,专门针对强化学习训练环境做了适配优化,尤其适用于需要可验证奖励信号的编程竞赛类任务,整体样本规模在10K到100K区间,语言为英语,可覆盖绝大多数主流编程竞赛的任务类型。数据集采用标准化Harbor任务布局,每个样本包含两大核心字段:path字段为格式为
将task_binary解压后即可获得完整的任务运行包,覆盖从任务提示、环境配置到结果验证的全流程所需文件:instruction.md为展示给智能体的标准化任务提示,对应编程竞赛的题干信息;environment/Dockerfile基于python:3.11-slim-bookworm镜像构建任务专属Python运行环境,可彻底解决不同训练平台的环境兼容性问题,保证任务运行的一致性;tests目录下的test.sh(验证器入口点)、verifier.py(确定性验证器实现)、verifier_data.json(验证器输入数据)共同组成了标准化自动验证体系,该验证器属于stdio_diff家族,通过运行智能体生成的/app/solution.py文件,对比隐藏的标准输入输出测试用例来自动评估解决方案的正确性,无需人工标注即可为强化学习训练提供稳定的奖励信号;此外任务包还包含记录来源信息的metadata.json、标注CPU/内存/超时等运行配置的task.toml文件,全面满足学术研究、工业研发的可复现要求。
为了保障大规模训练场景下的安全性与可复现性,本次数据集的转换过程设置了多维度的安全防护机制:所有数据集内容不会直接插值到shell、Python或Dockerfile源代码中,所有参数值均通过JSON文件传递;基础运行镜像固定,pip依赖通过严格允许列表正则表达式验证,避免恶意依赖注入;所有文本字段均经过控制字符过滤与长度限制,tarball路径经过专项验证防止路径遍历攻击;此外所有tar包均采用排序条目、固定时间戳和用户/组ID的确定性生成规则,保证同一任务的数据包哈希值唯一,符合科研可复现标准。
从应用价值来看,该数据集可广泛应用于多个技术研发场景:首先是强化学习代码智能体的专项训练,尤其是针对编程竞赛场景的长逻辑推理、复杂算法实现能力的调优,标准化的自动奖励验证机制可大幅降低训练过程中的人工标注成本;其次是代码大模型、AI编程工具的基准测试,行业可基于该数据集建立统一的算法能力评估标准,实现不同产品、不同模型的横向能力对比;此外还可用于强化学习算法研究,为结构化任务、长序列决策场景下的RL算法优化提供标准测试环境。
作为面向垂直场景的高质量标准化数据集,本次nemotron-gym-competitive-coding的发布,不仅降低了代码智能体研发的数据集准备门槛,也为编程竞赛场景下的AI能力评估建立了统一规范,对推动自动编程、代码推理领域的技术落地,完善AI训练数据集的标准化体系具有重要的参考意义。
查看nemotron-gym-competitive-coding
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)