

随着多语言自然语言处理(NLP)技术的快速落地,全球范围内对小语种、大语种细分场景的高质量标注数据集需求持续攀升。阿拉伯语作为22个阿拉伯国家的官方语言,全球使用人口超4亿,是数字经济全球化进程中不可忽视的重要语言板块,但长期以来,细粒度、跨领域、标注规范的阿拉伯语可读性评估语料相对稀缺,制约了阿拉伯语智能教育、内容分级、公共服务数字化等场景的产品研发进程。
作为全球领先的阿拉伯语计算研究机构,CAMeL Lab长期深耕阿拉伯语语料库建设、NLP技术研发等领域,其产出的多类数据集与工具已被全球学界、产业界广泛采用。本次发布的BAREC-Shared-Task-2026-sent数据集,是专门为「第二届阿拉伯语可读性评估共享任务(BAREC Shared Task 2026)」构建的大规模平衡式阿拉伯语可读性评估语料库,首发时间为2026年5月17日。
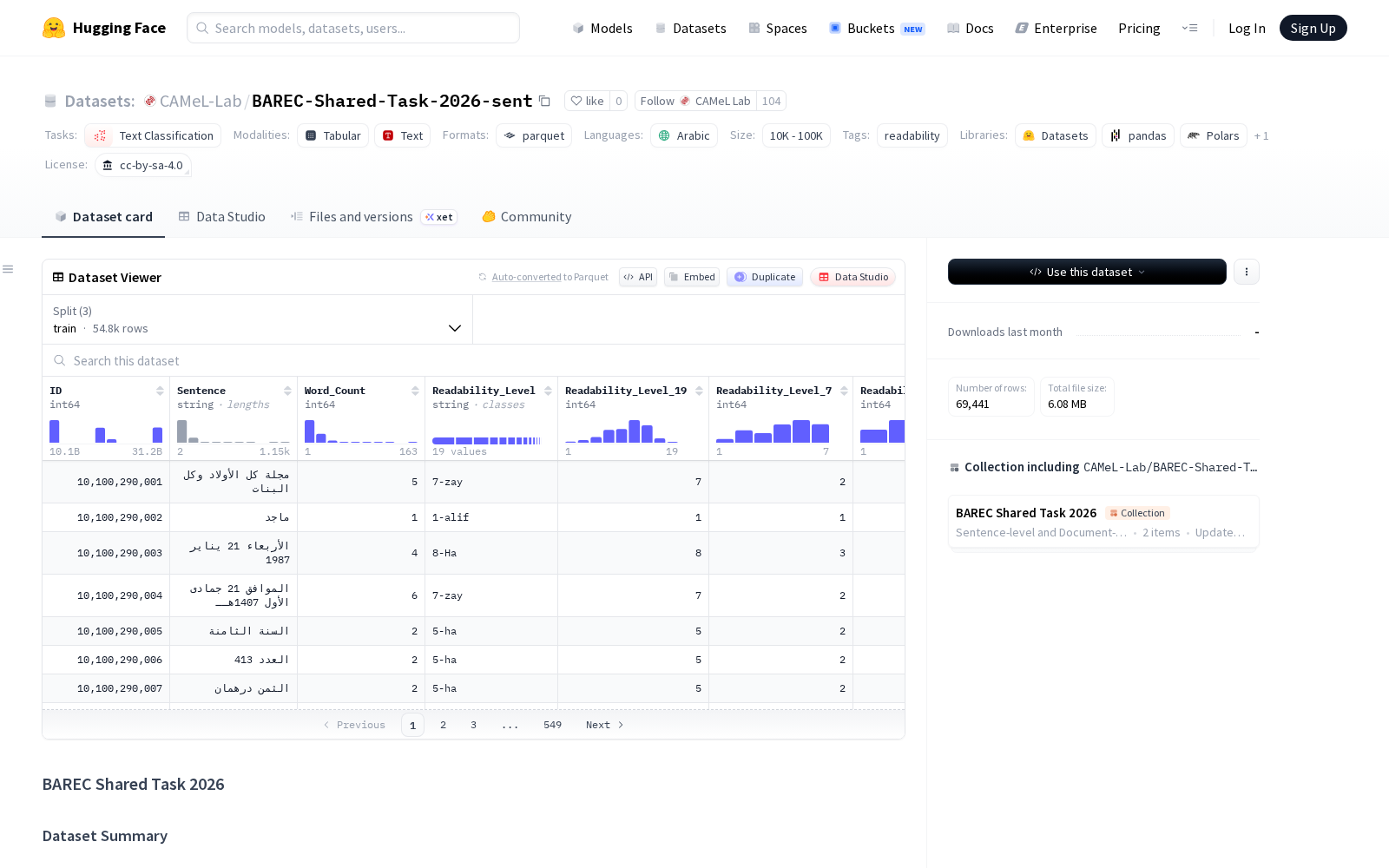
该数据集总词汇量超100万,全部采用句子级人工标注,核心标注体系设置了从「1-alif」到「19-qaf」的19个可读性梯度级别,同时提供向下映射的7级、5级、3级分类方案,可适配不同颗粒度的分类任务需求。值得关注的是,该数据集的文档级可读性得分由文档内部最难句子的19级标签决定,首次同时实现了句子级别、文档级别的双维度可读性信息标注,所有语料均为通用度更高的现代标准阿拉伯语(MSA)。
为进一步降低开发者的数据处理成本,该数据集的每个样本都配套了丰富的元数据字段,包括唯一句子ID、句子文本、单词数量、各级别可读性标签(同步提供数值和类别两种形式)、标注者ID、源文档文件名、文档来源、书籍信息、作者、所属领域(覆盖艺术与人文、STEM、社会科学三大类)、文本类别(分为基础、高级、专业三类)。数据集采用文档级划分逻辑,分为训练集(占比80%)、开发集(占比10%)、测试集(占比10%),划分过程中特别保障了不同可读性级别、不同领域、不同文本类别上的样本平衡性,可有效降低数据偏置对模型训练效果的干扰。
从应用场景来看,该数据集首先可直接用于阿拉伯语可读性自动评估模型的训练与评测,支撑阿拉伯语教育场景的教材难度匹配、学习者阅读内容智能推荐,公共服务场景的政务信息、科普内容可读性优化等产品研发;其次其多梯度的标签体系,也可作为序数文本分类任务的通用训练语料,支撑内容分级、信息优先级排序、多轮对话意图分类等NLP下游任务的开发;此外其跨领域、多等级的语料结构,还可为阿拉伯语文本风格识别、难度迁移等前沿研究提供数据支撑。该数据集的发布不仅为2026年BAREC共享任务提供了标准化的评测基准,也为全球阿拉伯语NLP开发者降低了训练数据获取门槛,对推动阿拉伯语数字内容生态的普惠化发展具有重要意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)