

近年具身智能赛道进入高速落地期,机器人学习、模仿学习作为支撑机器人自主完成复杂任务的核心技术,其研发效率高度依赖高质量、标准化的训练数据供给。此前不同研究机构、企业采集的机器人交互数据普遍存在格式不统一、标注规则差异大的问题,不同来源数据的复用需要投入大量的清洗、转换成本,成为制约行业研发效率的普遍痛点。针对这一问题,HuggingFace推出的LeRobot格式,专门为机器人学习场景设计了统一的数据存储、标注规范,目前已经成为全球机器人学习领域应用最广泛的通用数据集标准之一。
2026年5月18日,robot-learning团队正式发布符合LeRobot格式标准的ex2_all_v2_filtered数据集,本次发布的数据集首发上线HuggingFace平台,可为全球机器人学习领域的研发团队提供开箱即用的训练数据支撑。用户可通过以下链接访问数据集详情:查看ex2_all_v2_filtered
据了解,ex2_all_v2_filtered数据集主要面向机器人学习、模仿学习两大核心研发场景,依托统一的LeRobot格式,研发团队无需额外进行复杂的格式适配即可将数据集接入训练流程,可大幅降低数据预处理环节的人力与时间成本。从典型应用方向来看,该数据集可用于人形机器人日常操作技能的模仿训练、工业协作机器人的任务流程学习、具身智能多模态交互模型的迭代优化、机器人自主决策算法的泛化能力验证等多个场景,对推动机器人学习技术从实验室走向真实场景落地具有重要支撑作用。
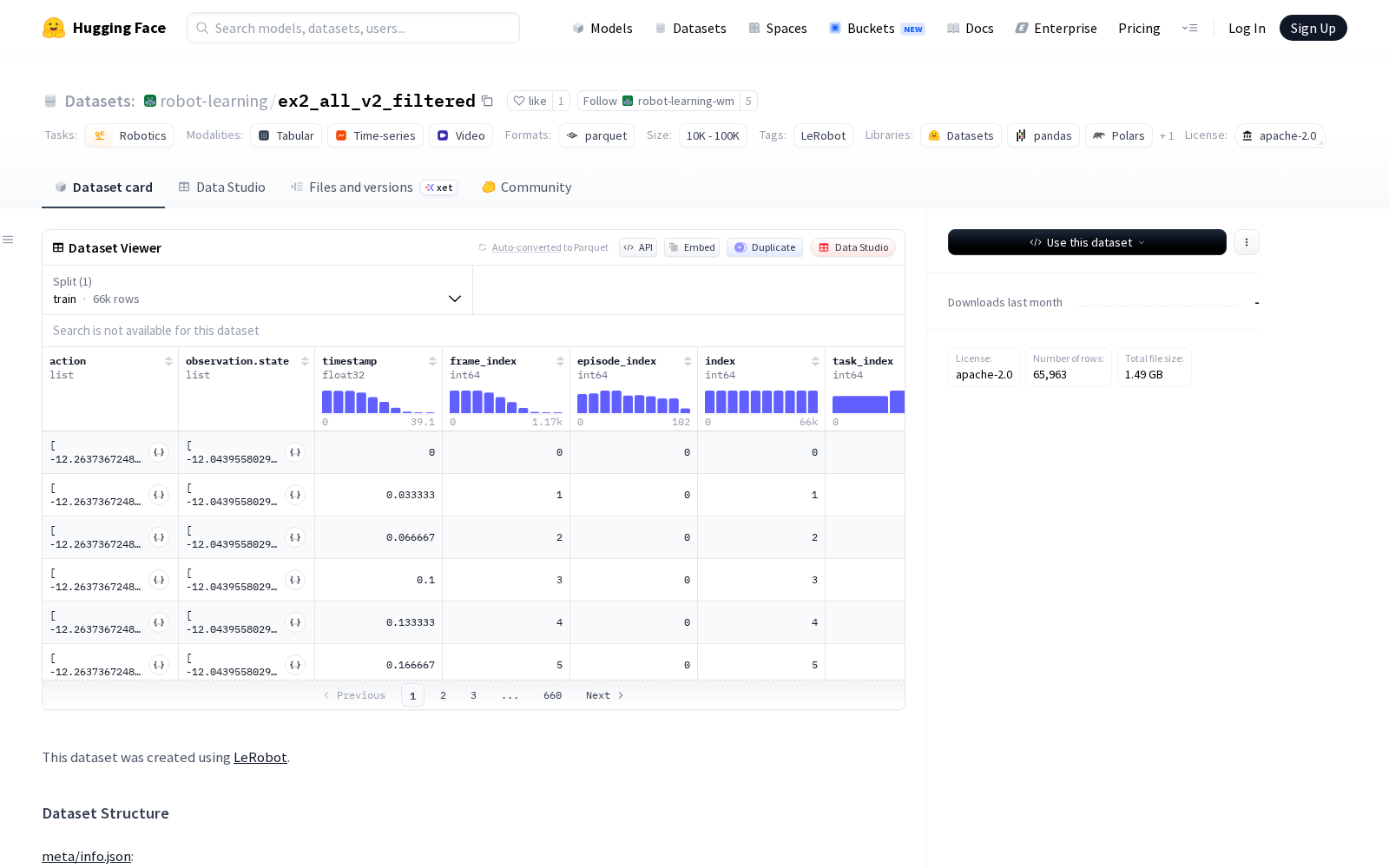
Dataset card内容:
Files and versions内容:
从行业发展层面来看,当前数据要素已经成为人工智能产业创新的核心生产资料,而具身智能领域的交互数据由于采集需要真实硬件部署、标注复杂度高,整体供给量远低于大语言模型等领域的训练数据规模。本次robot-learning开放的标准化数据集,不仅进一步丰富了全球机器人学习领域的高质量数据供给,也为中小研发团队降低技术门槛、加速技术迭代提供了普惠性支撑,对推动具身智能产业的商业化落地、完善数据要素在人工智能细分领域的流通应用体系具有积极意义。



_1769672084863.jpg)