

随着多语言大模型全球化布局加速,小语种高质量标注训练数据的稀缺正在成为AI技术落地不同区域市场的核心瓶颈。阿拉伯语作为联合国六大官方语言之一,覆盖中东、北非22个国家超4亿母语使用者,同时是全球超18亿穆斯林的宗教通用语言,在跨境交流、区域商业服务、宗教文化传播等场景下的NLP应用需求持续攀升,但此前行业内标准化、可商用的阿拉伯语标注数据集供给长期不足。
本次发布数据集的穆罕默德·本·扎耶德人工智能大学(Mohamed Bin Zayed University of Artificial Intelligence,简称MBZUAI)是阿联酋于2019年发起成立的全球首个专注人工智能领域的研究型高校,在多语言自然语言处理、计算机视觉、机器人学等领域拥有顶尖科研实力,也是中东地区AI技术创新与产业落地的核心枢纽。
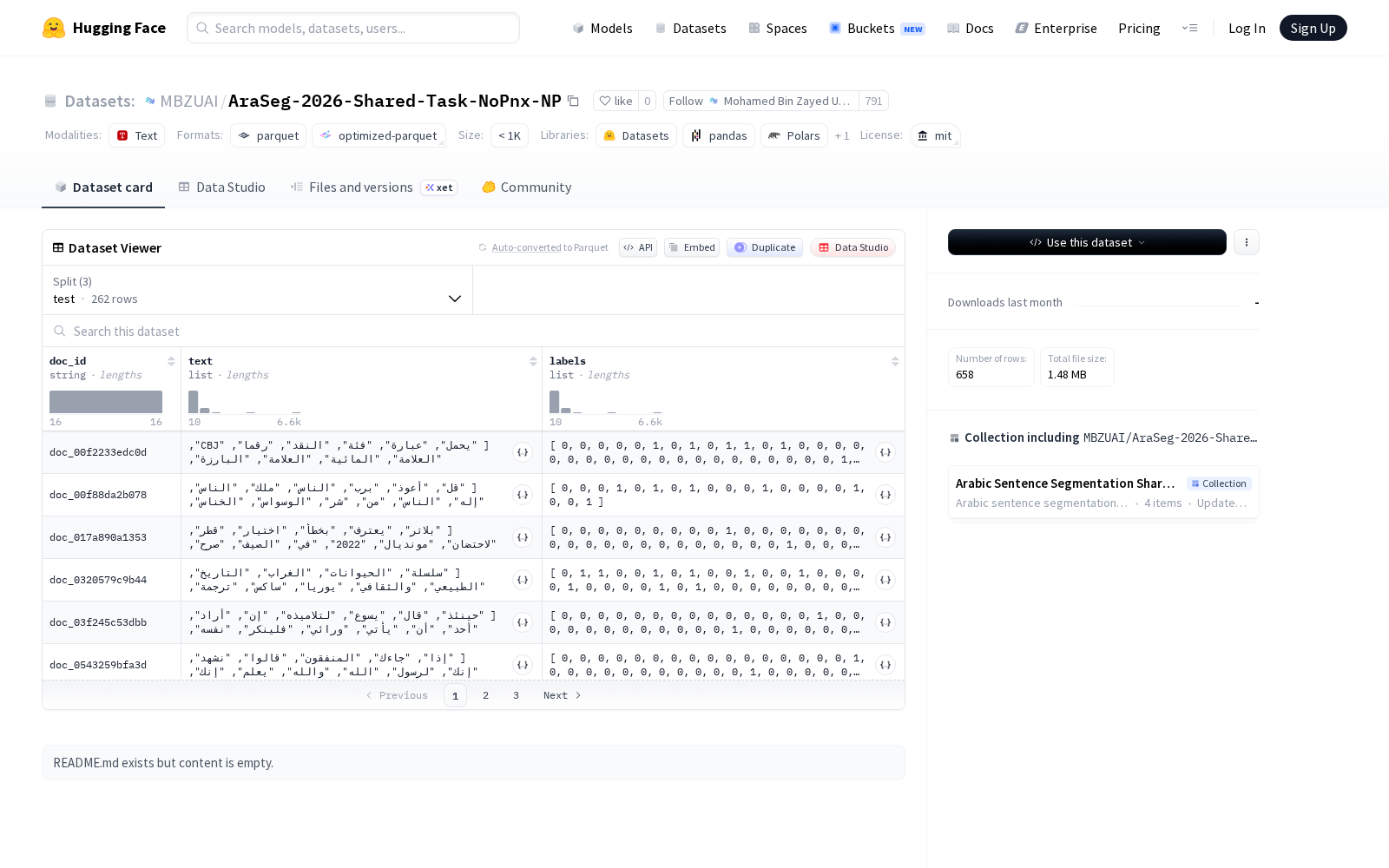
本次上线的AraSeg-2026-Shared-Task-NoPnx-NP是专门针对阿拉伯语场景设计的结构化文本分类数据集,采用对商业应用极为友好的MIT许可证发布,开发者可自由修改、分发甚至商用数据集内容。数据集共分为三个标准分割子集:训练集train_sampled含174个示例、开发集dev含222个示例、测试集test含262个示例,总容量约7.44MB。每个数据样本包含三个核心字段:doc_id为字符串类型的文档唯一标识符,text为字符串列表形式存储的文本内容,labels为64位整数列表形式的标注标签。整体数据采用分片文件格式组织,适配大模型训练阶段的并行加载需求,可直接用于文本分类、多标签分类或序列标注等主流自然语言处理任务。从数据结构设计来看,该数据集明确面向监督学习场景打造,其中text字段大概率存储分词后的阿拉伯语文本序列,labels字段则对应预设的分类或序列标注结果,可大幅降低开发者的数据预处理成本。
作为标准化的阿拉伯语标注数据集,AraSeg-2026-Shared-Task-NoPnx-NP可支撑多个领域的技术研发:在内容治理场景下可用于阿拉伯语社交媒体的违规内容识别、公共舆情监测;在商业服务场景下可用于阿拉伯语电商平台的商品评论情感分析、用户咨询意图识别;在文化与公共服务场景下可用于阿拉伯语教育的作文自动评分、宗教文本的结构化整理、伊斯兰金融服务的合规文本审核,同时也可作为基准数据集用于多语言大模型的阿拉伯语能力评测与优化。
该数据集的开源发布,不仅填补了阿拉伯语NLP领域高质量标注数据的供给缺口,也为全球小语种NLP数据集的标准化建设提供了参考范本。当前全球数据要素市场正处于高速发展阶段,多语言训练数据作为AI大模型全球化能力的核心支撑,其开放共享将有效降低中小AI企业进入区域市场的研发门槛,推动多语言AI技术的普惠落地,进一步释放不同语言文化场景下的数字经济价值。
查看AraSeg-2026-Shared-Task-NoPnx-NP
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)