

随着数字人文、自然语言处理(NLP)等交叉领域的快速发展,垂直领域的标注化历史文本数据正在成为科研创新的核心基础资源。近日,北欧顶尖数字人文研究机构、丹麦奥胡斯大学下属Center for Humanities Computing Aarhus(奥胡斯人文计算中心)正式对外发布danish-book-ads-raw-data数据集,该数据集首发于全球知名AI数据集与模型托管平台HuggingFace,为相关领域研究者提供了稀缺的小语种垂直场景数据选项。
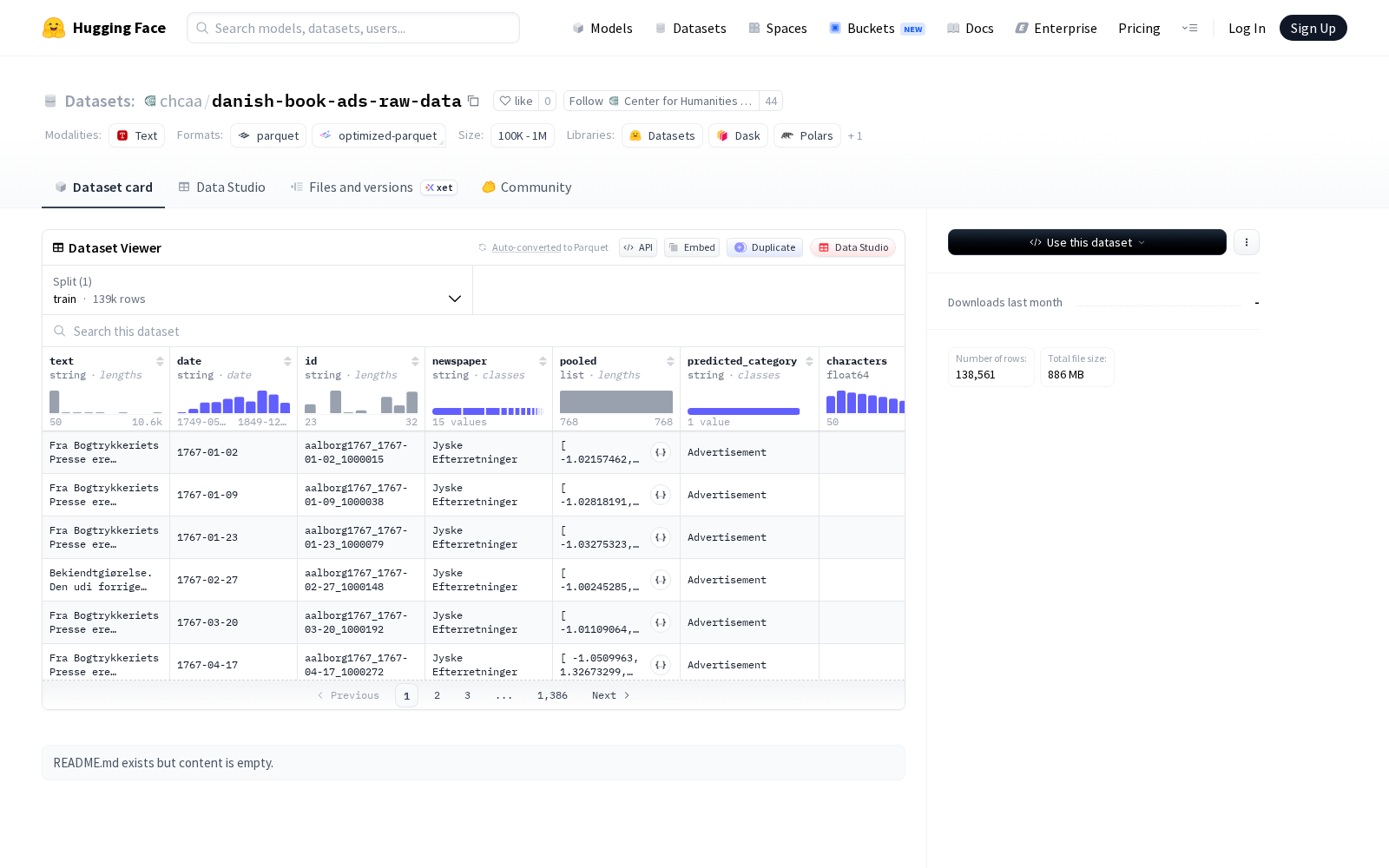
本次发布的danish-book-ads-raw-data数据集仅包含训练集,共计 138,561 个样本,数据总量约为 932 MB。每个样本覆盖10类结构化字段,具体包括:文本内容(text)、日期(date)、唯一标识符(id)、报纸来源(newspaper)、一个浮点数列表(pooled)、预测类别(predicted_category)、字符数(characters)、预测书籍公告(predicted_book_announce)、书籍公告(book_announce)以及评论(comment)。需要注意的是,目前该数据集公开的README信息中暂未披露数据集的具体背景、来源渠道、构建逻辑及官方推荐适用任务,相关使用者可结合自身研究需求进行筛选适配。
从字段属性来看,该数据集的应用场景覆盖多个研究与产业方向:在数字人文研究领域,研究者可通过不同时段、不同报纸平台的书籍广告投放数据,复盘丹麦出版行业的发展脉络、不同时期的读者阅读偏好变迁,以及出版机构的营销传播规律;在NLP技术研发领域,带标注的丹麦语文本可直接用于小语种文本分类、广告语义识别、印刷体历史文本OCR校正等模型的训练与测试,有效降低相关算法研发的标注成本;在传媒与出版产业研究领域,该数据集还可与图书销售数据、读者调研数据等联动,开展书籍广告投放效果的回溯分析,为当下的出版营销决策提供历史参照。
当前全球数据要素市场建设中,公共科研数据集是重要的公共创新基础设施,尤其是人文社科与技术交叉领域的结构化标注数据,长期存在供给不足的问题。本次奥胡斯人文计算中心发布的垂直领域数据集,不仅填补了丹麦语书籍广告类公开数据的空白,也为全球数字人文领域的跨区域、跨语言对比研究提供了新的数据源支撑。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)