

随着全球大语言模型(LLM)技术迭代进入深水区,行业对模型真实认知能力的评测需求持续升级,但现有主流基准测试体系长期存在两大核心痛点:要么评测内容过度偏向记忆性知识考查,模型可通过刷训练数据集获得虚高分数,无法反映真实推理能力;要么推理场景完全脱离现实业务,评测结果难以支撑落地选型需求,这一短板已成为制约大模型产业高质量发展的重要因素。
2026年5月19日,Meta旗下AI研究团队AI at Meta正式在Hugging Face平台发布全新基准测试数据集Grounded Integration Measure(简称GIM),精准瞄准上述行业空白,为大模型认知整合能力的量化评测提供了全新解决方案。
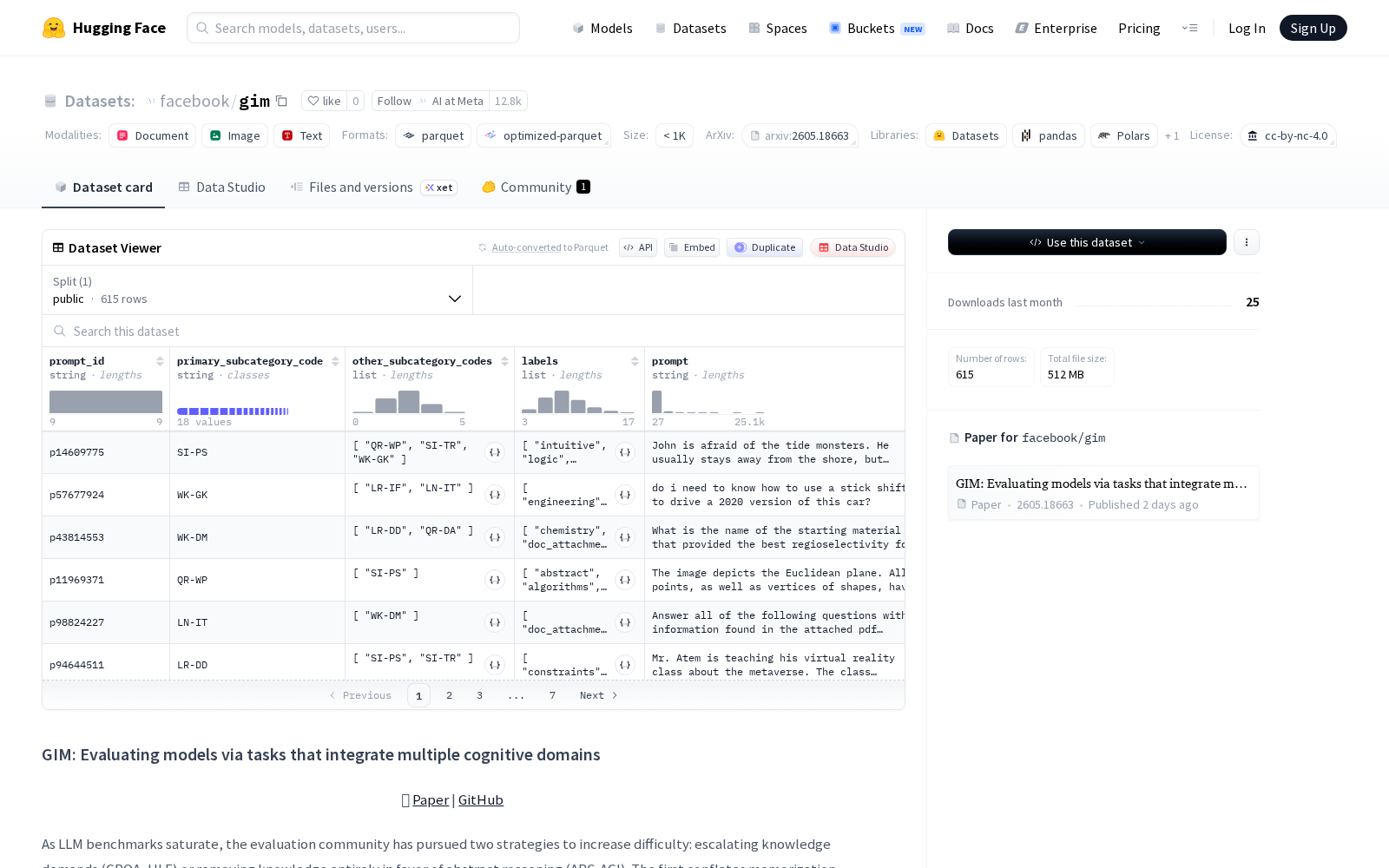
据官方介绍,GIM的核心创新点在于通过“多认知操作整合”的设计逻辑提升评测的真实性与区分度:整个数据集包含820道由行业专家原创设计的测试问题,其中615道对外开放、205道设为私有测试集,每道问题都要求模型协同完成约束满足、状态跟踪、认知警惕、受众校准等多种复杂认知操作,且所有题目都基于大众可广泛获取的通用常识设计,无需专业领域知识储备即可作答,从设计根源上确保评测结果完全贴合现实任务的能力要求。
为进一步提升评测的可信度,GIM绝大多数问题都配套了拆解式的详细评分规则,中位数可达6个独立评判维度,可有效避免单一评分标准带来的结果偏差。同时,数据集采用公开-私有分割设计,内置了专门的数据污染诊断机制,可有效识别大模型训练阶段提前“接触”测试题导致的成绩失真问题。研究团队还基于超过20万条提示-响应对,在28个不同参数规模的大模型上完成了2参数逻辑(2PL)项目反应理论(IRT)模型的校准,该框架可生成高度可靠的模型能力估计值,即便原始准确率因错误、缺失数据出现失真,仍可实现不同测试配置的精准排序,稳定性远超传统的单一准确率评测方法。
目前GIM数据集可支撑多维度的产业与研究应用:不仅可直接生成覆盖22个主流大模型、47个测试配置(独特模型×思维层级对)的综合性能排行榜,为行业用户选型、厂商迭代模型提供参考;还可用于开展测试阶段计算资源(如思维链令牌数量)与模型性能的权衡研究,为大模型落地阶段的成本优化、资源配置提供量化依据。本次官方同步开放了完整的评估框架、校准后的IRT参数以及所有公开问题,全球研发机构与企业均可免费获取使用。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)