

随着多模态大模型技术的快速迭代,实时流式视频理解能力已经成为AI技术落地文娱、安防、出行、教育等多场景的核心能力支撑,但长期以来,行业内缺乏针对主动式、全模态流式视频理解的统一评测基准,不同模型的能力评估维度分散、可比性弱,成为制约相关技术规模化落地的重要瓶颈。
2026年5月18日,中国人民大学联合腾讯微信视觉团队共同打造的OMNIPRO数据集正式首发于arXiv,这也是国内首个全主动流式视频理解综合基准数据集,将为流式视频理解模型的能力评估提供统一的评测框架。
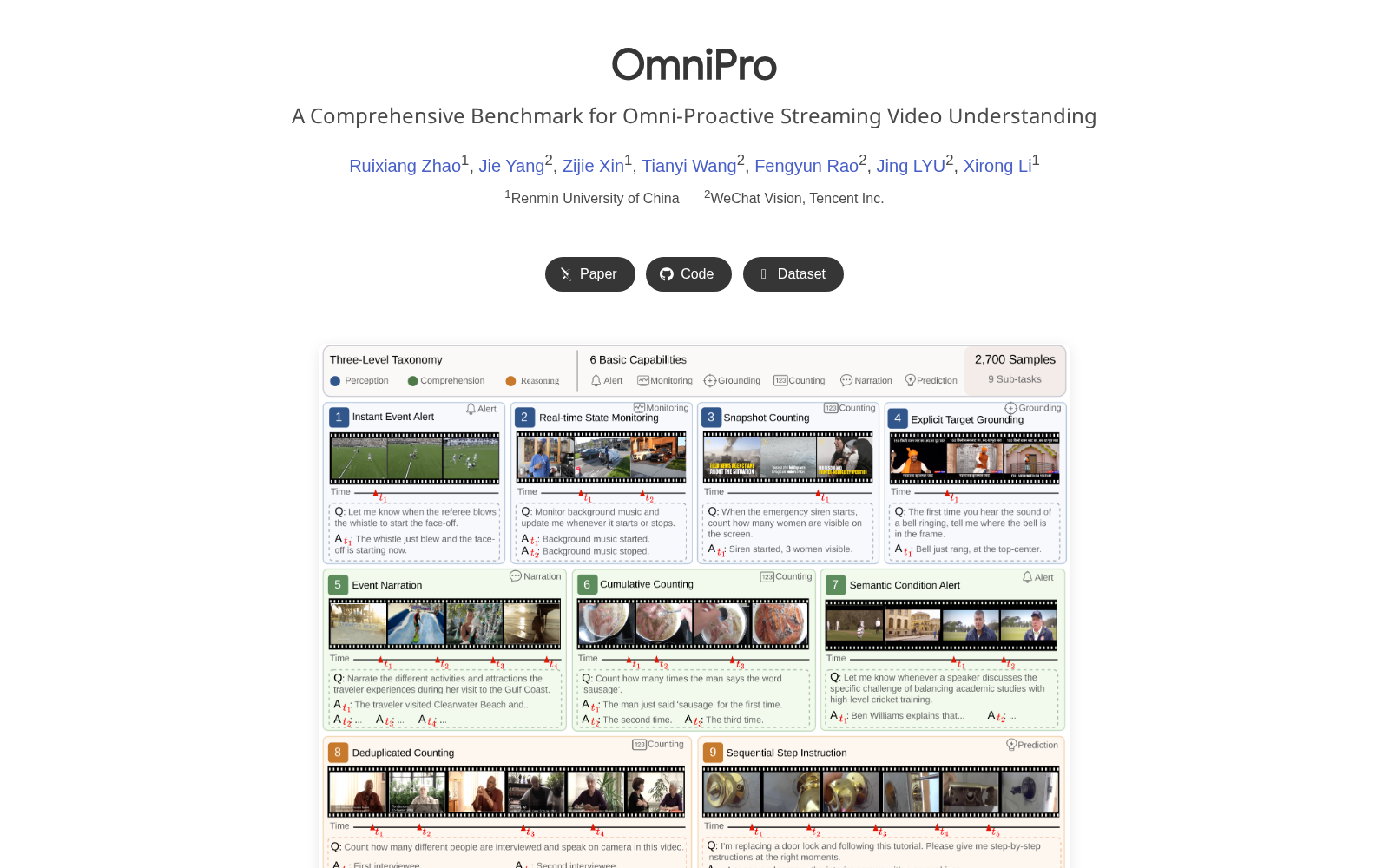
据介绍,OMNIPRO数据集共包含2700个经过人工验证的高质量样本,覆盖9个子任务、3个认知层次,全面覆盖6种基本视频理解能力,其中84%的样本需要依赖音频信号(包括语音和非语音类信号)完成判断,对大模型的多模态协同感知能力提出了更贴合真实场景的要求。数据集的源视频全部来自LongVALE和COIN两个公开数据集的测试集,共涉及1771个源视频,研发团队通过Gemini 3 Flash模型生成了多模态密集描述与结构化问答对,保障了数据集标注的规范性和覆盖度。该数据集的核心定位是系统评估大模型在全模态感知、主动响应决策、多样化视频理解任务中的协同能力,解决了传统视频评测数据集仅针对预录制内容、静态任务设计的缺陷。
从潜在应用方向来看,OMNIPRO数据集的评测能力可覆盖多个产业场景:在内容平台领域,可用于评估多模态模型对短视频流、直播流的实时内容审核、合规预警能力;在城市治理领域,可支撑安防监控模型的实时异常事件识别、主动告警能力验证;在智慧出行领域,可用于智能座舱多模态交互模型的驾驶员状态感知、动态指令响应能力评测;在在线教育领域,也可为课堂实时注意力分析、互动教学响应等场景的模型研发提供评测基准。
作为AI产业发展的核心基础设施,高质量基准数据集的供给是数据要素市场在AI领域落地的重要体现,OMNIPRO的发布不仅填补了国内流式视频主动理解领域的评测标准空白,也为全球多模态感知技术的评估提供了新的参考维度,能够有效降低相关研发团队的评测成本,统一行业能力评估口径,加速多模态大模型在实时交互场景的落地进程,为数字经济场景的智能化升级提供底层技术支撑。
详情页内容:



_1769672084863.jpg)