

当前,随着扩散模型等AIGC技术的快速普及,图像编辑、深度伪造的技术门槛持续降低,篡改后的图像内容逼真度不断提升,在新闻传播、社交网络、司法取证等多个场景带来的内容真实性风险日益凸显。而现阶段主流的图像篡改检测模型普遍存在泛化能力短板:面对不同来源的图像、不同类型的篡改手法、不同尺寸的篡改区域时,检测准确率往往会出现大幅下滑,行业亟需覆盖多维度场景的高质量基准数据集,为算法研发与性能验证提供统一标尺。近日,由波士顿大学牵头、多所高校联合构建的大规模图像篡改检测基准数据集AUDITS正式发布,该成果于2026年5月20日首发于学术预印本平台arXiv,瞄准现有检测模型在多轴分布偏移下的性能痛点,为计算机视觉安全、AIGC内容识别领域的研究与落地提供核心数据支撑。
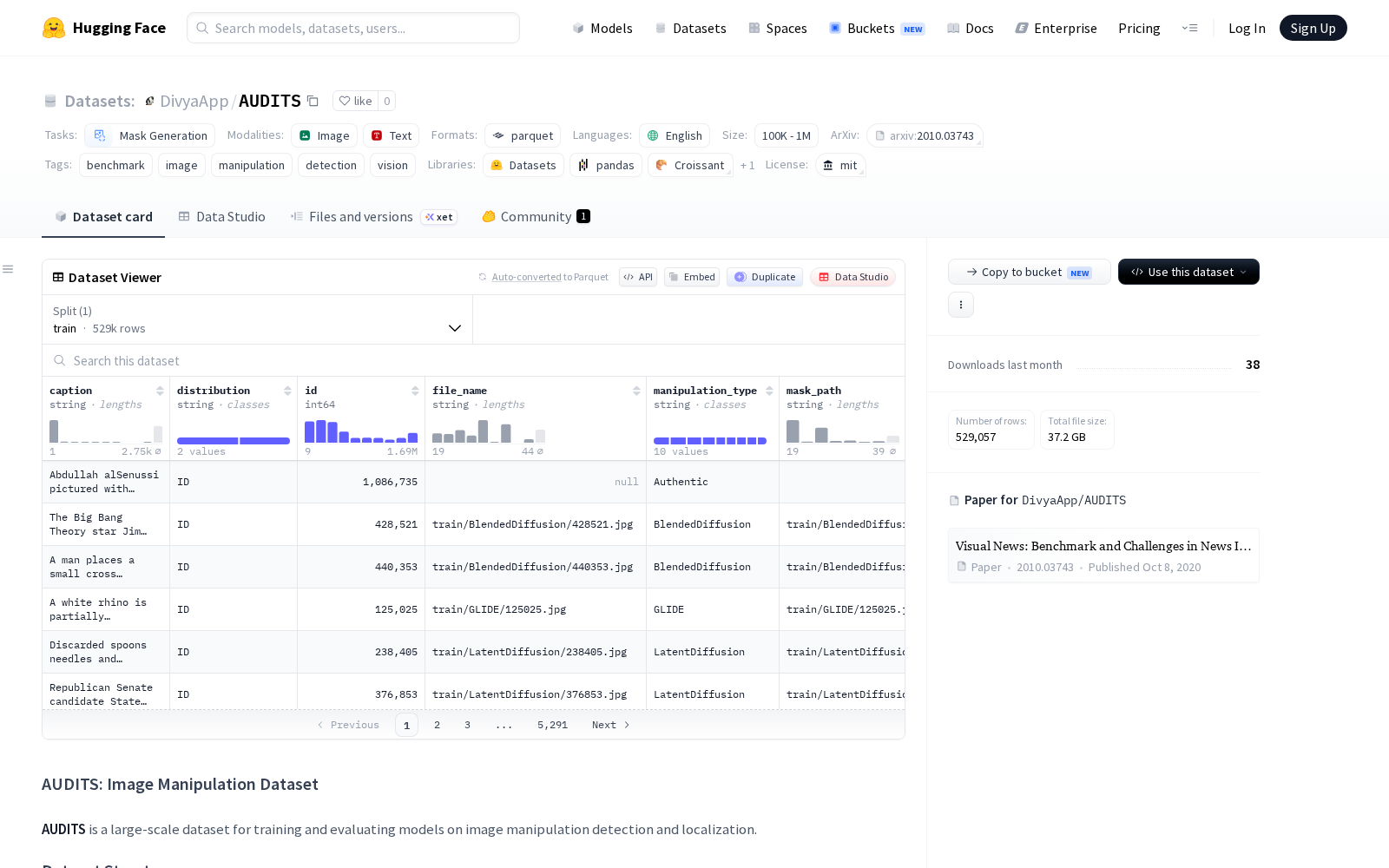
据公开资料显示,AUDITS数据集共包含53万余张图像-掩码对,基础数据源覆盖COCO通用视觉数据集、VisualNews新闻视觉数据集两大主流视觉域,能够覆盖普通生活场景、专业新闻场景两类最广泛的图像应用场景;篡改内容生成环节采用11种当前业界主流的扩散模型图像编辑技术,覆盖内容替换、元素移除、对象插入三类最高发的图像篡改操作,同时将篡改区域面积占比控制在1%到100%的区间内,覆盖从微小细节篡改到全图伪造的全场景需求。为了避免数据集的场景偏向性,研发团队通过精心设计的采样策略,确保数据集在图像主题、新闻来源、对象类别上具备广泛的分布多样性,同时额外引入了人类感知质量标注维度,能够支撑研究人员评估篡改内容的逼真度对检测模型性能的影响,填补了此前同类数据集缺乏感知质量维度标注的空白。
作为面向计算机视觉安全领域的基准数据集,AUDITS的典型应用场景覆盖学术研究、产业落地多个维度:在学术研究层面,可作为通用基准评估不同篡改检测模型在跨域、跨篡改类型、跨篡改尺寸下的泛化能力,为算法迭代提供统一的测试标尺;在产业应用层面,可支撑社交平台虚假内容核验系统、新闻机构内容真实性校验工具、司法电子证据鉴定系统、AIGC平台合规检测模块的开发与性能优化,助力落地更可靠的图像内容安全防护能力。当前全球数据要素市场中,垂直领域的高质量标注数据集是AI技术研发的核心基础设施,尤其是内容安全领域的基准数据集,直接关系到数字内容信任体系的构建效率。AUDITS数据集的发布,为解决当前篡改检测技术泛化能力不足的行业痛点提供了关键数据支撑,将推动图像篡改检测、扩散模型生成内容识别等领域的技术落地进程。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)