

随着全球大语言模型技术与多语言AI应用的快速发展,区域语种高质量标注训练数据的供给缺口,已经成为制约不同地区数字化转型、AI技术普惠落地的核心瓶颈之一。阿拉伯语作为全球22个国家的官方语言,覆盖超4亿使用人口,在中东、北非区域的政务、商业、民生场景中有着极高的应用需求,但此前适配NLP研发需求的结构化标注数据集供给相对有限。
总部位于阿联酋阿布扎比的穆罕默德·本·扎耶德人工智能大学(MBZUAI)是全球首个专注人工智能领域的研究生教育与前沿研究机构,长期深耕多语言自然语言处理、计算机视觉、机器学习等核心AI领域的技术研发与产业转化,是中东区域AI技术创新的核心枢纽。2026年5月18日,该机构正式在全球最大的AI模型与数据集开源平台HuggingFace上线AraSeg-2026-Shared-Task-NoPnx-PA数据集,为阿拉伯语NLP研发提供标准化的训练数据支撑。
本次发布的AraSeg-2026-Shared-Task-NoPnx-PA属于文本分类与序列标注类专项数据集,总样本量约13453条,按照NLP研发的标准流程划分为三大子集:包含3514条样本的训练采样集(train_sampled)、包含5066条样本的开发集(dev)、包含4873条样本的测试集(test)。每个样本设置四个标准化字段:字符串类型的文档ID(doc_id)、整型的段落ID(paragraph_id)、字符串列表形式的文本内容(text),以及整型列表形式的对应标签(labels),整体以结构化格式存储,可直接适配自然语言处理领域中文本分类、序列标注两类核心任务的训练、验证、测试全流程需求。
查看AraSeg-2026-Shared-Task-NoPnx-PA完整数据集信息
Dataset card内容:
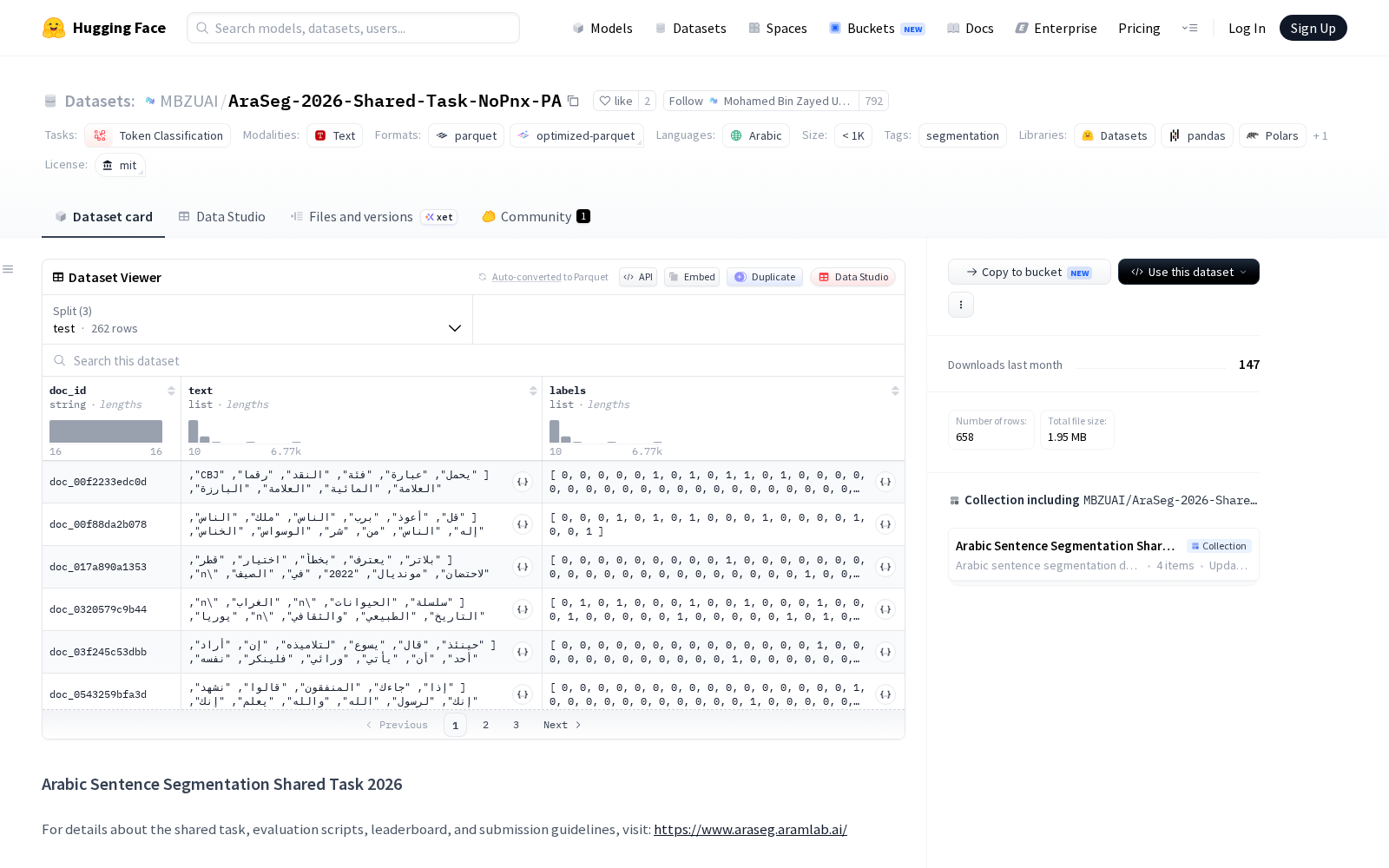
Files and versions内容:
从应用价值来看,该数据集可广泛适配阿拉伯语场景下的多类NLP应用研发:例如政务场景的阿拉伯语官方文档自动分类与信息抽取、商业场景的阿拉伯语电商评论情感分析与用户意图识别、公共服务场景的阿拉伯语社交媒体舆情监测与内容审核、产业场景的阿拉伯语专业文献结构化处理与命名实体识别等,能够大幅降低相关领域AI模型的研发训练成本。当前全球数据要素市场正进入垂直化、场景化、区域化供给的发展阶段,针对特定语种的高质量标注数据集,既是支撑AI技术全球化落地的核心基础资源,也是推动不同区域数字经济均衡发展、缩小语种间数字鸿沟的重要抓手,本次AraSeg-2026数据集的发布,也将为中东、北非区域的数字化转型与AI产业生态建设提供重要的数据支撑。



_1769672084863.jpg)