

随着大模型产业进入落地深水区,长上下文理解能力已经成为大模型适配法律审阅、文档解析、多文档问答等企业级场景的核心竞争力,与之对应的标准化评测工具链也成为行业刚需。RULER作为当前业内应用最广泛的长上下文性能评测套件,可通过“大海捞针(NIAH)”、多跳问答等任务,量化评估大模型在超长上下文窗口下的信息召回准确率、推理能力,但其此前的上游数据依赖存在适配成本高、可选范围有限等痛点,也成为限制评测效率的重要因素。
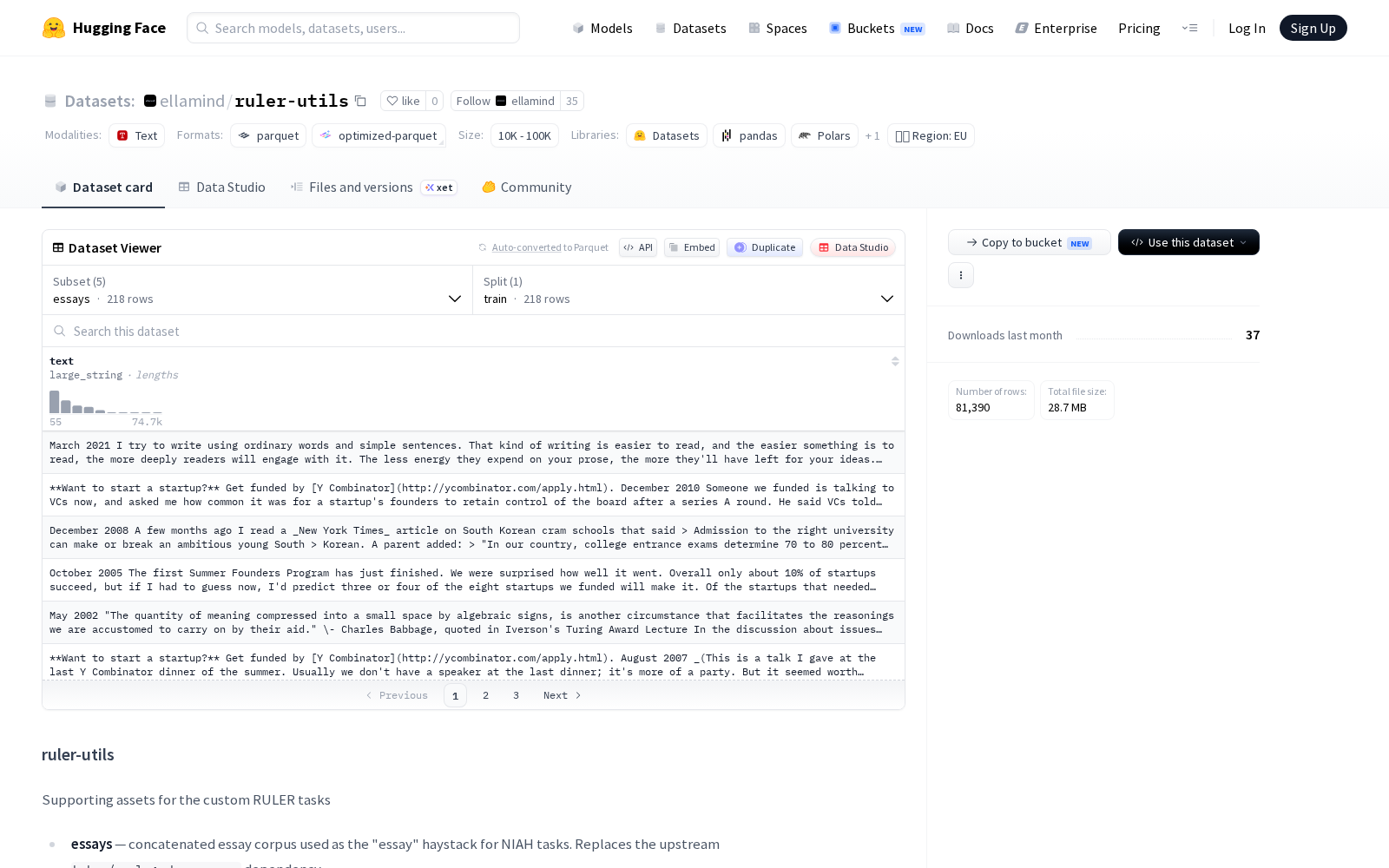
ellamind本次发布的数据集ruler-utils,正是针对上述痛点打造的专用支持资产集合,包含五个独立配置的数据文件,所有数据均以Parquet格式存储,并统一标记为训练分割,旨在支持问答(QA)和信息检索相关任务的评估与开发。其中essays配置提供了一个串联的文章语料库,作为 NIAH(Needle in a Haystack)任务的“essay”干草堆,替代了上游的 `baber/paul_graham_essays` 依赖,省去开发者额外适配上游数据源的环节;squad_docs 和 squad_qas 配置分别包含了为 `ruler_qa_squad` 任务预处理的 SQuAD-v2 数据集上下文和问题,SQuAD-v2是斯坦福大学开源的主流抽取式问答基准数据集,预加工后的版本可直接接入评测流程,无需额外进行数据清洗、格式转换;hotpot_docs 和 hotpot_qas 配置则包含了为 `ruler_qa_hotpot` 任务预处理的 HotpotQA 数据集干扰上下文和问题,可用于测试大模型在多文档干扰下的跨源信息推理、无效内容过滤能力。
从应用场景来看,ruler-utils数据集可覆盖多个产业与研究场景的潜在需求:在大模型研发侧,厂商可基于该数据集快速搭建长上下文能力评测pipeline,对不同版本大模型的上下文窗口准确率、信息召回率等核心指标进行横向对比,支撑长上下文大模型的迭代优化;在应用开发侧,开放域信息检索系统、企业知识库问答、智能文档处理产品的开发者,可利用该数据集对产品的检索精度、多文档信息整合能力进行基准测试,提升落地场景的可靠性;在学术研究侧,自然语言处理领域的研究者可直接调用该数据集开展长文本理解、多跳问答相关的算法研究,降低前期数据准备的时间成本。
当前全球数据要素市场中,高质量的AI训练与评测数据集是AI产业发展的核心公共基础设施,本次ellamind发布的ruler-utils数据集,进一步完善了长上下文大模型评测的工具链,为行业提供了低门槛、标准化的评测数据资产,对推动大模型长文本能力的标准化评估、加速长上下文相关应用的规模化落地具有积极意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)