

随着全球自然语言处理(NLP)技术向细分区域、细分场景落地,小语种高质量标注数据集的缺口正成为制约区域数字经济发展的核心瓶颈之一。阿拉伯语作为全球22个国家的官方语言、覆盖超4.2亿使用者的通用语言,此前在文本分割、序列标注等下游NLP任务领域,始终缺乏经过标准化标注、可直接用于模型训练的开源数据集资源。
作为全球首个专注人工智能领域研究的研究生级高等院校,总部位于阿联酋阿布扎比的穆罕默德·本·扎耶德人工智能大学(Mohamed Bin Zayed University of Artificial Intelligence,简称MBZUAI)长期深耕阿拉伯语AI技术研发,是中东及北非(MENA)区域人工智能基础设施建设的核心参与方,本次发布的AraSeg-2026-Shared-Task-Pnx-NP是其在阿拉伯语NLP数据资源建设领域的最新成果,于2026年5月18日首次上线全球最大AI开源社区HuggingFace。
Mohamed Bin Zayed University of Artificial Intelligence本次发布的数据集AraSeg-2026-Shared-Task-Pnx-NP,该数据集包含三个预定义的数据分割:测试集(test,262个样本)、开发集(dev,222个样本)和采样训练集(train_sampled,174个样本)。每个数据样本由三个字段构成:一个字符串类型的文档ID(doc_id)、一个字符串列表类型的文本内容(text),以及一个整型列表类型的标签(labels)。数据集总大小约为8.6 MB。
从技术应用路径来看,该标准化标注数据集可广泛支撑多类阿拉伯语NLP应用的研发工作:在消费互联网场景中,可用于阿拉伯语智能客服的意图分词与实体抽取、阿拉伯语社交平台的内容合规审核、语音转写结果的文本结构化处理;在产业与公共服务场景中,可支撑阿拉伯语政务文档的自动分类与标签生成、阿拉伯语古籍数字化项目的内容拆解、跨境电商平台阿拉伯语商品描述的自动标注等多个方向的模型训练与效果验证,有效降低相关研发团队的标注成本,缩短模型迭代周期。
本次数据集的开源发布,也是全球数据要素跨区域共享、小语种数字基础设施共建的典型实践。据公开行业数据显示,中东及北非区域数字经济增速已连续3年位居全球前列,阿拉伯语AI技术的商业化需求持续攀升,高质量开源数据集的持续供给,将进一步降低中小科技团队的研发门槛,推动区域AI应用的普惠化落地,为全球多语种AI生态的均衡发展提供支撑。
查看AraSeg-2026-Shared-Task-Pnx-NP
Dataset card内容:
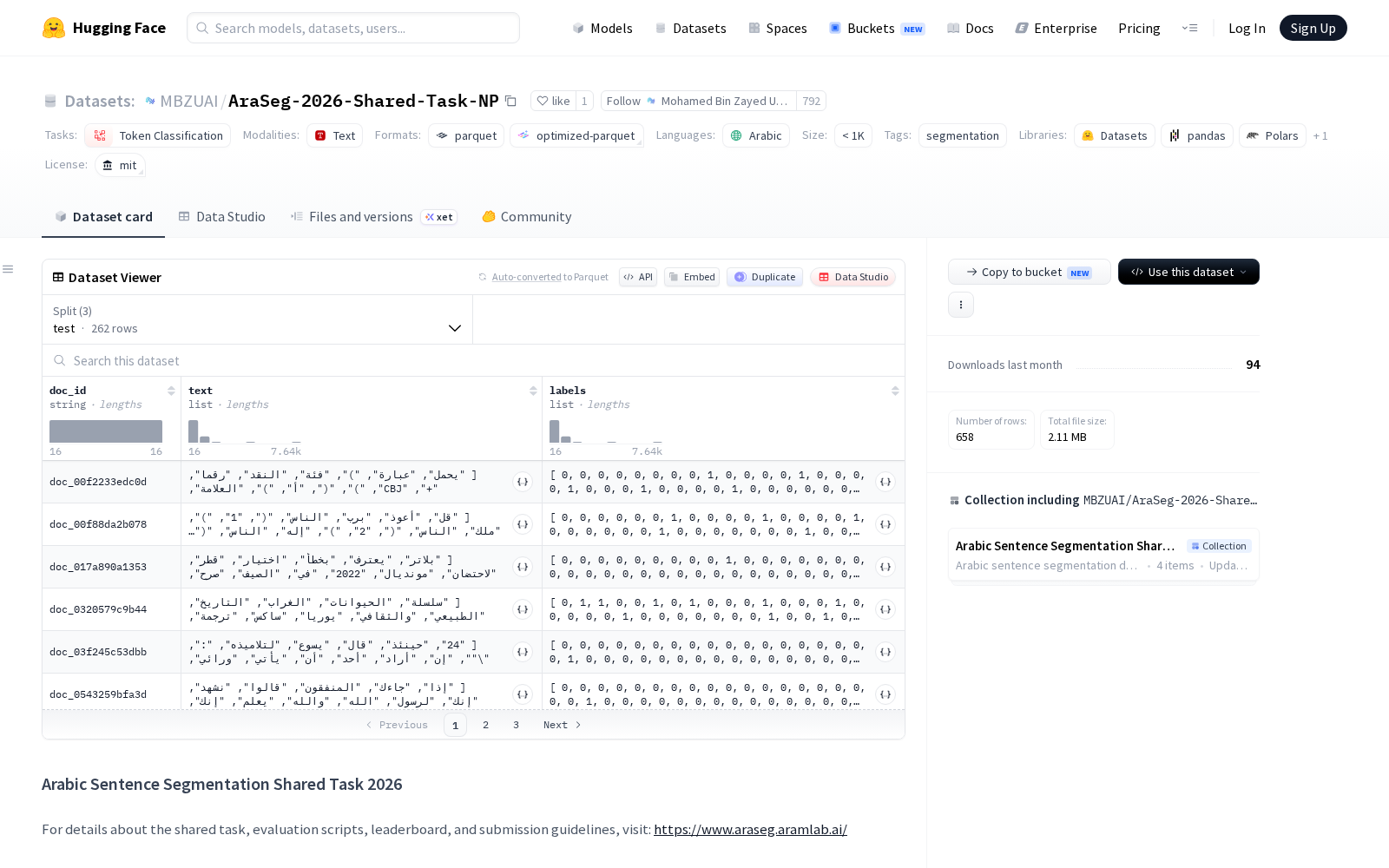
Files and versions内容:



_1769672084863.jpg)