

随着大模型技术在各行业的落地深化,文本重排作为信息检索、检索增强生成(RAG)、智能问答等场景的核心环节,其精度直接决定了AI系统的输出质量。交叉编码器(Cross-Encoders)凭借比双编码器更高的语义匹配精度,已成为当前工业级重排方案的主流技术路线,但长期以来,适配交叉编码器训练的大规模、多领域、低标注成本数据集供给不足,一直是制约相关技术落地效率的核心瓶颈。
近日,Sentence Transformers旗下Cross-Encoders项目正式发布ettin-reranker-v1-data数据集,该数据集于2026年5月19日率先在HuggingFace平台上线,面向全球AI开发者开放使用。作为专门为交叉编码器重排模型训练打造的大规模文本对数据集,ettin-reranker-v1-data混合了广泛领域的原生文本对、经强教师重排器重新评分的检索对两类数据,所有相关性标签均由自动化评分系统生成,无需人工标注,大幅降低了重排模型训练的数据获取门槛。
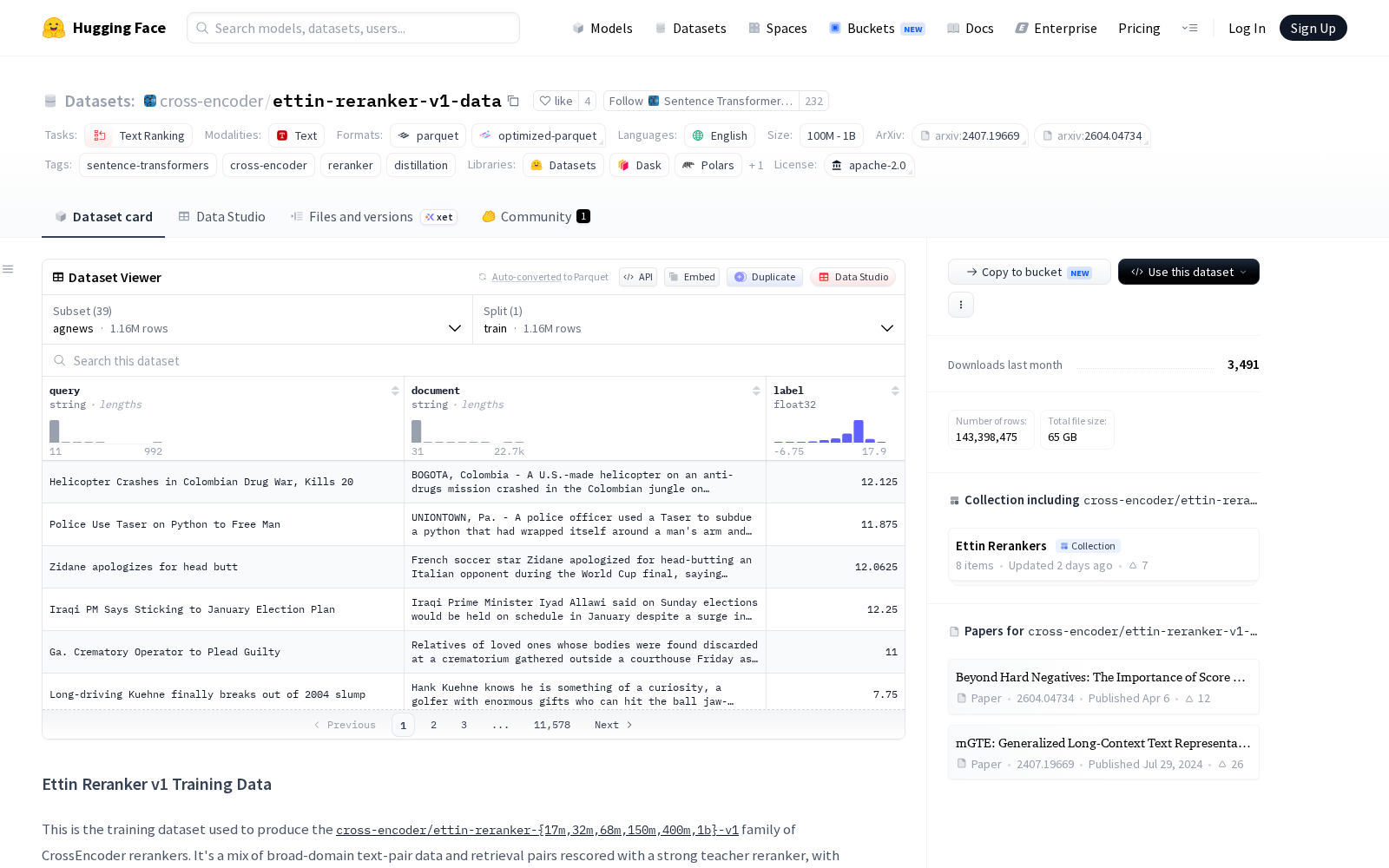
该数据集覆盖多个细分场景子集(配置),包含agnews、amazon_reviews、arxiv_title_abstract、msmarco等分支,涵盖新闻资讯、电商产品评论、学术论文标题与摘要匹配、通用问答、社交媒体内容等多种主流文本类型。每个样本统一设置三个字段:query(查询或锚句子)、document(候选文档或句子)、label(浮点型相关性或相似性分数),适配不同任务的训练逻辑。从规模来看,数据集总样本量处于1亿到10亿区间,单个子集样本量从数万到500万不等,既可以支持小范围垂直场景的重排模型微调,也能够满足大规模通用重排模型预训练的样本量需求。
从应用价值来看,ettin-reranker-v1-data专为文本排名任务设计,除了支持sentence-transformers交叉编码器等主流重排模型的训练与评估之外,可覆盖的典型应用场景包括:第一,通用与垂直领域信息检索系统优化,比如搜索引擎结果排序、企业内部知识库检索结果匹配、政务服务平台办事入口检索效率提升等,可有效降低无效信息返回率,提升用户检索体验;第二,RAG系统的重排环节定制,作为当前大模型落地企业场景的主流方案,RAG的重排环节直接决定了召回上下文与用户问题的匹配度,进而影响大模型回答的准确性,该数据集可适配不同行业RAG系统的重排模型训练需求;第三,智能问答、语义相似度计算等场景,比如智能客服的问题-答案匹配、内容平台的相似内容推荐、侵权内容识别、多语言文本对齐等任务的模型训练与效果验证。
据公开信息显示,该数据集的原始素材均来自sentence-transformers、nomic、BEIR等业内公认的权威公开数据集,后续通过lightonai/embeddings-pre-training等成熟中间数据集完成标准化预处理与多源数据整合,保障了不同来源数据的格式一致性与标注逻辑统一性,可直接接入现有模型训练管线,减少开发者的数据清洗工作量。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)