

随着大模型产业落地加速,语义检索、交叉重排序等核心技术的迭代对高质量标注训练数据集的需求持续攀升,检索增强生成(RAG)、开放域问答等场景普遍面临数据集分散、标注标准不统一、规模不足等痛点。近日,Sentence Transformers旗下交叉编码器(Cross-Encoders)项目正式推出lightonai-embeddings-fine-tuning-reranked-v1数据集,该数据集于2026年5月18日首发上线HuggingFace平台,是目前覆盖场景最全面的大规模信息检索与问答基准数据集之一。
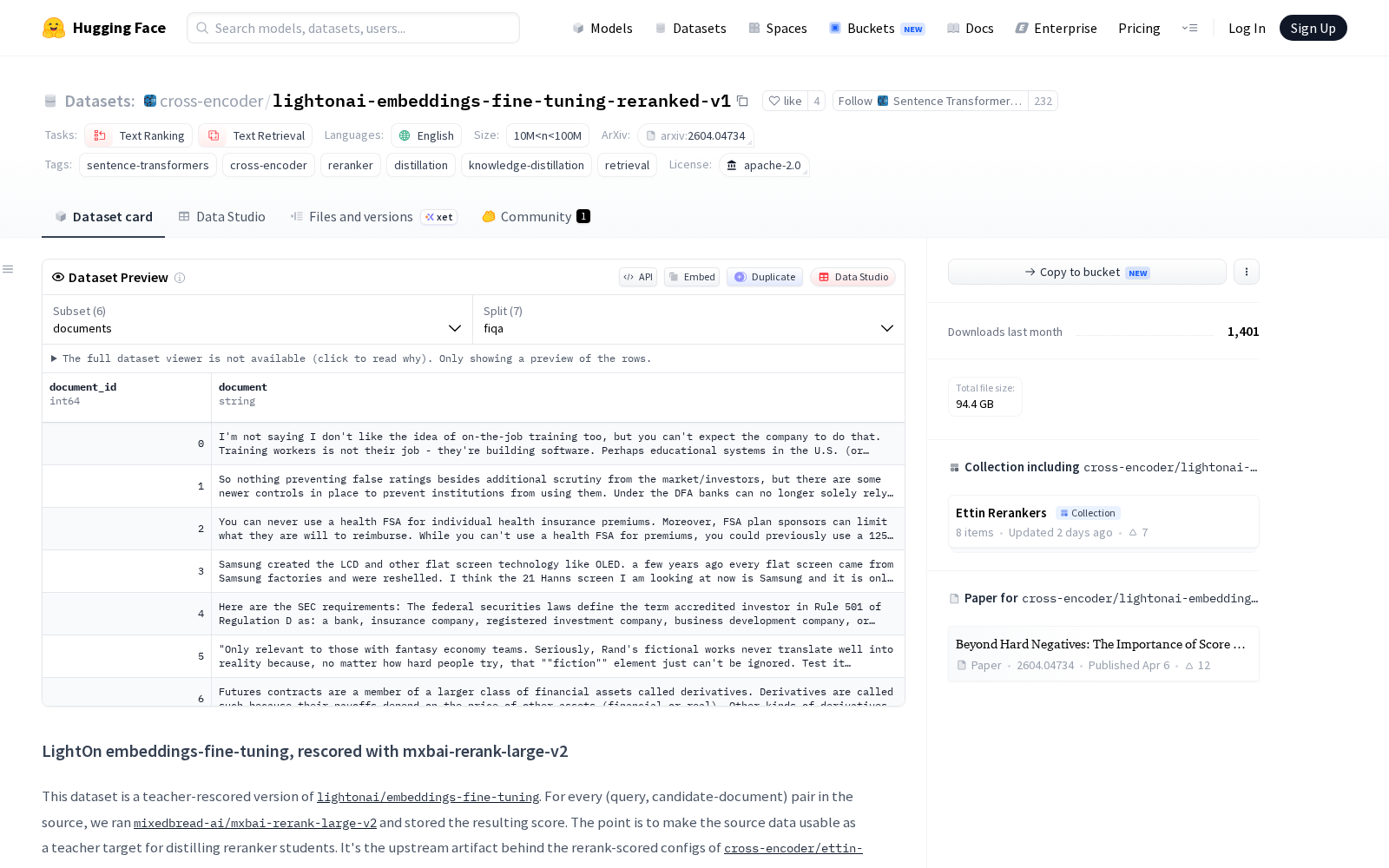
本次发布的数据集整合了fiqa(金融问答基准)、hotpotqa(多跳推理问答基准)、msmarco(微软大规模网页搜索基准)、nq(自然问题问答基准)、fever(事实验证基准)、squadv2(斯坦福问答基准)、trivia(常识问答基准)共7个全球范围内广泛使用的知名开源数据集,形成了覆盖多行业、多任务类型的统一标注数据集,解决了此前研发团队需要跨平台整合多源数据、对齐标注标准的繁琐问题。
该数据集核心包含三类标注数据:一是文档数据,覆盖文档ID与文档内容文本,总样本量超4600万条,覆盖金融、科技、常识、政务等多领域内容;二是查询数据,包含查询ID与用户查询文本,总样本量约110万条,覆盖真实用户搜索、问答场景的典型需求;三是相关性评分数据,包含查询ID、候选文档ID列表、对应相关性分数列表以及正例文档ID列表,可直接用于训练和评估检索模型的相关性判断能力。为适配不同研发场景的资源需求,数据集还提供了三种评分数据变体:scores_merged(多源数据合并版本)、scores_subsampled(子采样轻量版本)和scores_merged_subsampled(合并子采样版本),其中轻量版本可满足小规模实验、快速验证算法效果的需求,全量合并版本可用于工业级大规模模型的训练调优。全数据集总大小覆盖23.8GB到46.3GB不等,可支持信息检索、开放域问答、文档排序、神经网络检索模型(包括双编码器、交叉编码器)等多类技术方向的训练与评估需求。
从落地应用来看,该数据集可广泛应用于多个数字化场景:在企业知识库、政务公开平台等场景中,基于该数据集训练的文档排序模型可大幅提升搜索结果与用户需求的匹配精度,降低用户信息获取成本;在大模型RAG系统建设中,该数据集可用于优化召回层与重排序层的模型效果,减少大模型回答幻觉,提升开放域问答的准确率与可信度;在检索技术研发领域,该数据集统一的标注标准也可作为通用benchmark用于不同检索算法的性能对比,推动整个语义检索技术领域的迭代升级。作为AI训练数据要素的核心组成部分,该高质量基准数据集的发布也将进一步降低检索类AI技术的研发门槛,加速相关技术在各行业的落地进程。
查看lightonai-embeddings-fine-tuning-reranked-v1
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)