

随着全球多语种大模型产业的快速发展,小语种大模型的训练数据供给不足、尤其是高质量偏好对齐数据缺口较大,已成为制约非英语大模型性能提升的核心瓶颈。传统用于DPO/ORPO等对齐训练的偏好数据集,其被拒绝(rejected)负样本大多来自通用弱基线模型,与待对齐模型的实际能力断层较大,对比信号针对性不足,往往会拉长对齐训练周期、降低对齐效率,增加不必要的算力消耗。
2026年5月17日,德国科技公司Mayflower GmbH正式在HuggingFace平台上线名为boldt-dc-1b-orpo-onpolicy-de(又称Boldt-DC-1B On-Policy ORPO (German))的德语专属偏好数据集,瞄准上述行业痛点提供了新的解决方案。
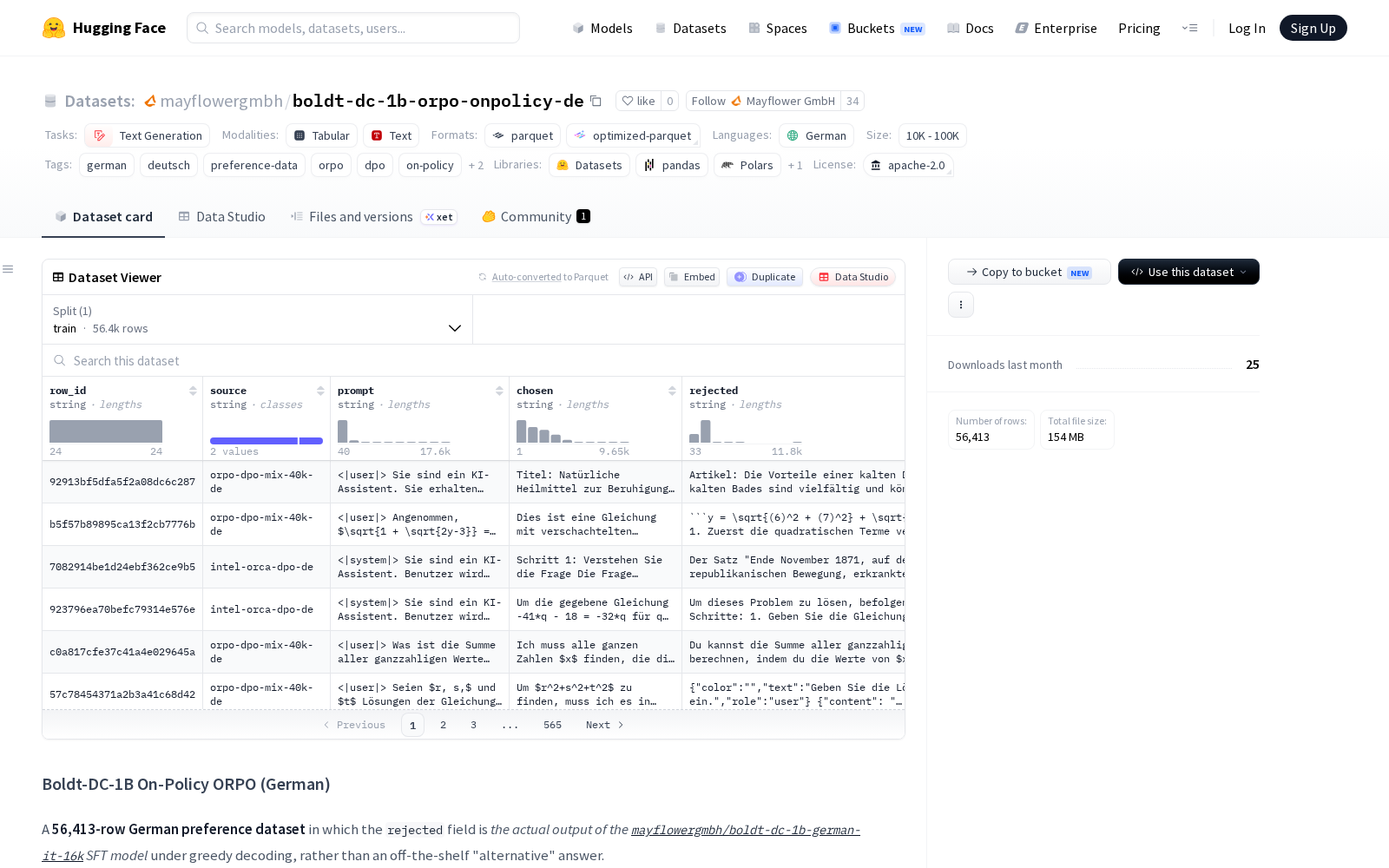
该数据集共包含56413个标注样本,由orpo-dpo-mix-40k-de、intel-orca-dpo-de两大公开德语偏好源数据集合并、去重后构建而成,每个样本覆盖经Boldt聊天令牌格式化的对话历史提示(prompt)、源数据集优选助手响应(chosen)、指定SFT模型生成的贪婪延续响应(rejected)、原始被拒响应(original_rejected)等共计15个字段,同时配套提供token长度统计、生成参数(模型、引擎、种子、温度)、拒绝响应标记(is_refusal)等完整元数据,方便开发者和研究者根据需求灵活调用、开展控制变量实验。
该数据集的核心差异化优势在于其负样本构建逻辑:不同于传统偏好数据集采用通用弱基线生成被拒响应的方案,本次发布的数据集的rejected样本全部由经过监督微调的特定模型mayflowergmbh/boldt-dc-1b-german-it-16k在贪婪解码策略下生成,能够直接针对该模型当前的实际失败模式输出对比信号,大幅提升对齐训练的针对性,降低无效训练的资源消耗。
根据官方说明,该数据集的核心应用场景包括两方面:一是用于boldt-dc-1b-german-it-16k模型及其相近衍生版本的偏好对齐微调,快速提升模型的响应质量与人类偏好匹配度;二是用于分析该12.5亿参数规模Llama架构SFT模型的特定故障模式,为小参数大模型的训练优化提供研究素材。除此之外,该数据集也可作为德语大模型对齐算法的基准测试数据、小语种偏好数据集构建方案的参考样本,支撑德语大模型产业的相关技术研发。
官方同时提示,该数据集的对比信号强度因样本而异,chosen响应的质量依赖于源数据集的标注水平,且数据集中观察到的重复、幻觉等模式仅适用于12.5亿参数规模的Llama架构SFT模型,迁移至其他参数规模、其他架构的大模型训练时需提前验证适配性。
从数据要素产业的视角来看,本次定制化偏好数据集的发布,不仅填补了1B级德语大模型对齐训练的细分数据缺口,也为全球小语种大模型训练数据的生产提供了可参考的范式:针对待优化模型的实际能力定制负样本,能够在有限的数据规模下最大化对齐效率,这对于降低小语种大模型的训练成本、加速非英语大模型的普及落地具有重要的参考价值。
查看boldt-dc-1b-orpo-onpolicy-de
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)