

当前多语言自然语言处理(NLP)已成为大模型全球化落地的核心赛道,阿拉伯语作为联合国六大官方语言之一,覆盖全球22个国家和地区超4亿使用者,但其高质量标注语料的稀缺始终是制约阿拉伯语NLP技术发展的核心瓶颈,尤其是可读性分级这类需要精细化人工标注的垂直领域数据集供给长期不足。近日,全球顶尖的阿拉伯语计算建模研究机构CAMeL Lab正式上线BAREC-Shared-Task-2026-doc数据集,该数据集专为BAREC 2026共享任务设计,是目前阿拉伯语领域规模最大的细粒度可读性评估标注语料库之一。
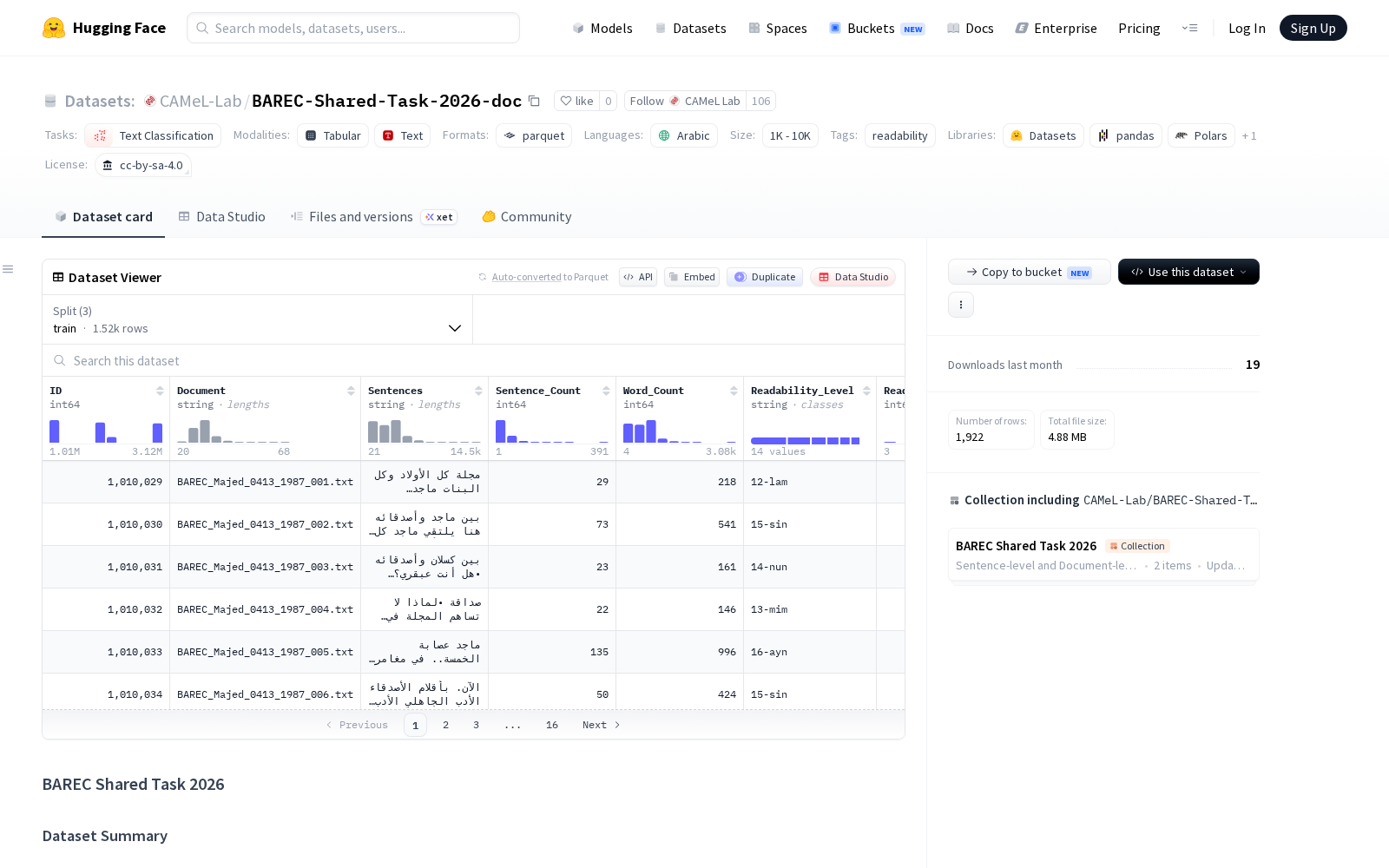
本次发布的数据集总规模超100万词,核心特色在于采用多粒度分级标注体系:在句子级别标注了19个精细可读性等级,同时提供了映射到7级、5级、3级的粗粒度分类方案,文档级可读性分数则基于文档内难度最高句子的19级标注结果确定,可同时支撑不同精度要求的多类别可读性分类任务。数据集字段覆盖完整,除基础的ID、文档文件名、句子文本、句子数量、词数等元信息外,还包含各级可读性标签、文本来源、所属书籍、作者信息、所属领域(覆盖艺术与人文、STEM、社会科学三大类)、文本类别(分为基础、高级、专业三类),可支撑多维度的交叉研究需求。
为保证模型训练和评估的科学性,本次发布的数据集全部采用现代标准阿拉伯语语料,按照8:1:1的比例划分为训练集、开发集和测试集,且在可读性等级、内容领域、文本类别三个维度均做了分布平衡处理,可有效避免数据偏置对模型效果的干扰。对应的评估任务被定义为序数分类,配套提供了多维度评估指标体系,包含19级、7级、5级、3级分类准确率,±1相邻准确率,平均绝对误差,二次加权Kappa等,为共享任务参赛团队及后续相关研究提供了统一的效果衡量标准。
从应用价值来看,该数据集的落地场景十分广泛:在教育领域,可用于阿拉伯语教材分级、课外阅读内容智能匹配,为不同语言水平的学习者精准适配学习资源;在公共服务领域,可支撑政府公告、医疗科普等公共信息的易读性转化,提升低识字群体的公共服务获取效率;在内容平台场景,可实现新闻、网文、音视频脚本的自动难度分级,优化内容推荐的精准度;同时也可作为训练数据,优化阿拉伯语大模型的输出可读性适配能力,满足不同用户群体的内容需求,对推动阿拉伯语地区的数字化普及、消除数字鸿沟具备潜在的社会价值。作为阿拉伯语NLP领域稀缺的高质量标注数据集,本次发布也将为全球多语言NLP技术的普惠发展提供重要的基础数据支撑。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)