

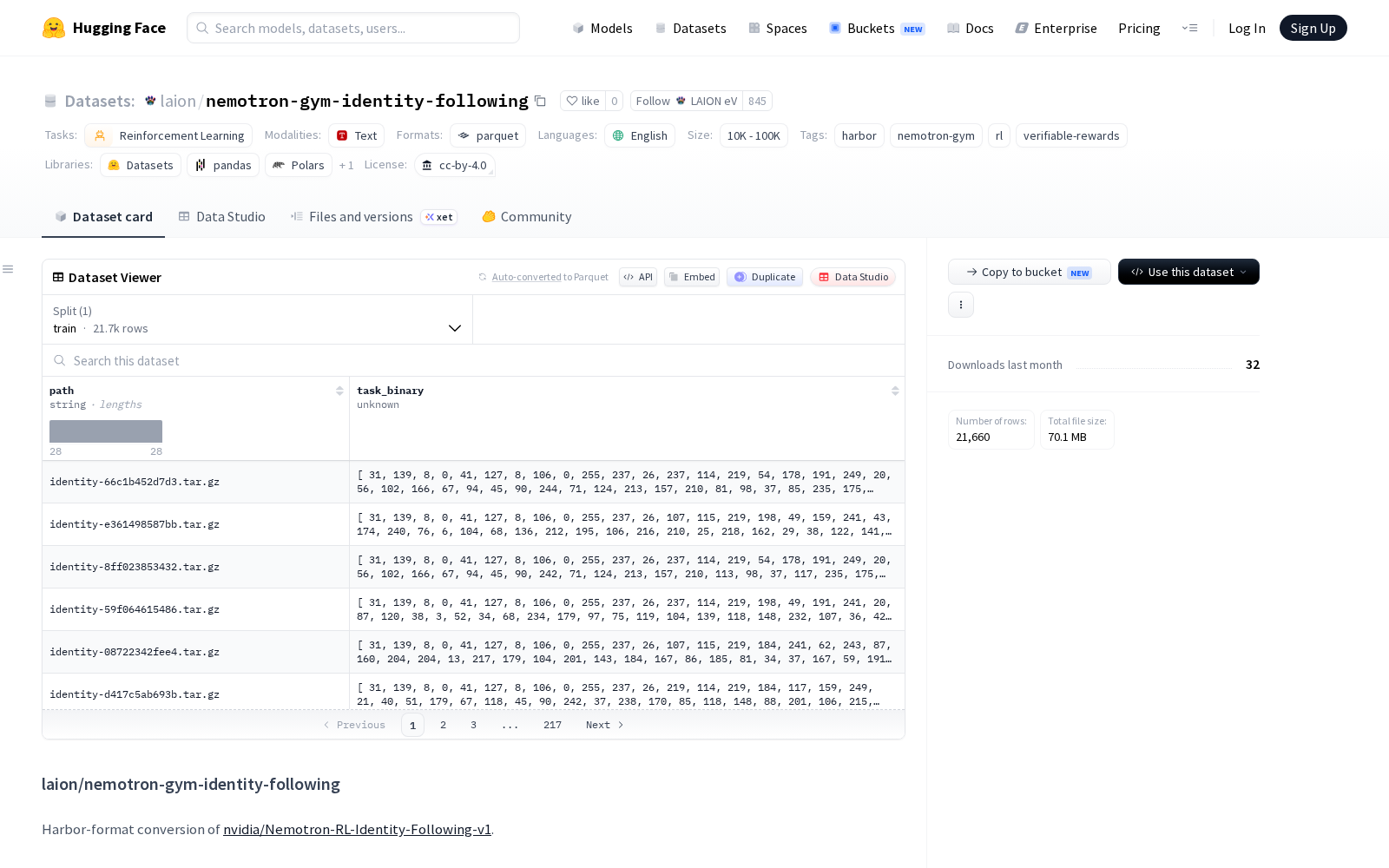
当前生成式AI与强化学习(RL)技术落地过程中,智能体身份漂移、奖励机制不可验证、训练环境难以复现已成为制约AI对齐、AI Agent落地的核心痛点,针对细分场景的标准化、高可信训练数据集也成为AI基础设施建设的重要方向。2026年5月16日,LAION eV正式发布的nemotron-gym-identity-following数据集,正是面向这一行业需求推出的专项训练资源。据介绍,该数据集是nvidia/Nemotron-RL-Identity-Following-v1数据集的Harbor格式转换版本,属于NVIDIA NeMo-Gym开源集合的组成部分,专为强化学习任务设计,样本规模处于1万至10万区间,核心围绕身份遵循(identity-following)场景的训练与验证需求构建。
从数据构成来看,每个样本包含两大核心字段:path字段为符合`
为保障数据集的安全性与可复现性,本次转换过程全程遵循安全构建原则:数据集内容不会被直接插值到shell、Python或Dockerfile源代码中,所有参数统一通过tests/verifier_data.json传递,从源头避免代码注入风险;基础镜像名称固定、pip依赖通过严格允许列表正则表达式验证,杜绝非授权依赖引入的安全隐患;文本字段全部去除C0/C1控制字符并限制长度,tarball路径经过遍历/NUL/绝对路径攻击验证,进一步降低恶意攻击可能性。同时所有tarball采用确定性构建规则(排序条目、mtime=0、uid/gid=0),确保不同环境下的字节级可重现,解决了传统强化学习数据集训练结果难以复现的行业共性问题。
该数据集的验证器家族为llm_judge,采用LiteLLM框架,默认调用openai/gpt-4o-mini模型针对特定角色原则进行评分,可直接支撑强化学习奖励机制的可验证性测试。目前该数据集可广泛应用于AI Agent身份一致性训练、企业定制大模型人设对齐、多智能体协作场景的角色权责匹配、强化学习奖励机制可解释性研究、AI安全对齐测试等多个领域,尤其适配对任务环境安全性、可复现性要求较高的研发场景。作为当前AI训练数据细分场景的重要补充,该数据集的发布不仅填补了身份遵循类强化学习开源数据集的供给缺口,其安全构建、可验证、可复现的设计思路,也为AI训练数据集的标准化、可信化建设提供了参考样本,对推动强化学习技术落地、完善AI基础设施生态具有积极意义。
查看nemotron-gym-identity-following
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)