

当前视觉语言模型(VLM)已成为多模态大模型领域的核心发展方向,广泛应用于视觉问答、智能座舱环境感知、内容审核、工业缺陷检测、辅助医疗影像判读等多个场景,但行业长期面临一个共性痛点:当VLM在多模态任务中输出错误结果时,研究者很难精准判断问题出自底层视觉感知能力不足,还是高层逻辑推理能力缺陷,这也导致VLM的后训练往往采用感知、推理混合的粗放模式,训练效率低、能力瓶颈定位难。近日,加州大学圣克鲁兹分校视觉语言与多模态分析实验室(UCSC-VLAA)正式发布VLM-CapCurriculum-Perception-Data(简称D_perc)数据集,该成果源自其入选ICML 2026的论文《从看见到思考:解耦感知与推理改进视觉语言模型的后训练》,为解决上述行业痛点提供了可行的工具方案。
和普通VLM训练数据集不同,VLM-CapCurriculum-Perception-Data的核心设计思路是实现感知能力与推理能力的完全解耦:所有样本均为专门构造的四选一多选题,问题仅通过细粒度的图像观察即可得出正确答案,完全不需要复杂逻辑推理,但未经过专项感知训练的通用强VLM却大概率会答错。通过这种特殊构造,数据集可以完全隔离模型的感知失败与推理失败,专门用于VLM底层视觉感知能力的训练与评估,彻底解决了此前VLM能力评估维度模糊、问题定位难的问题。
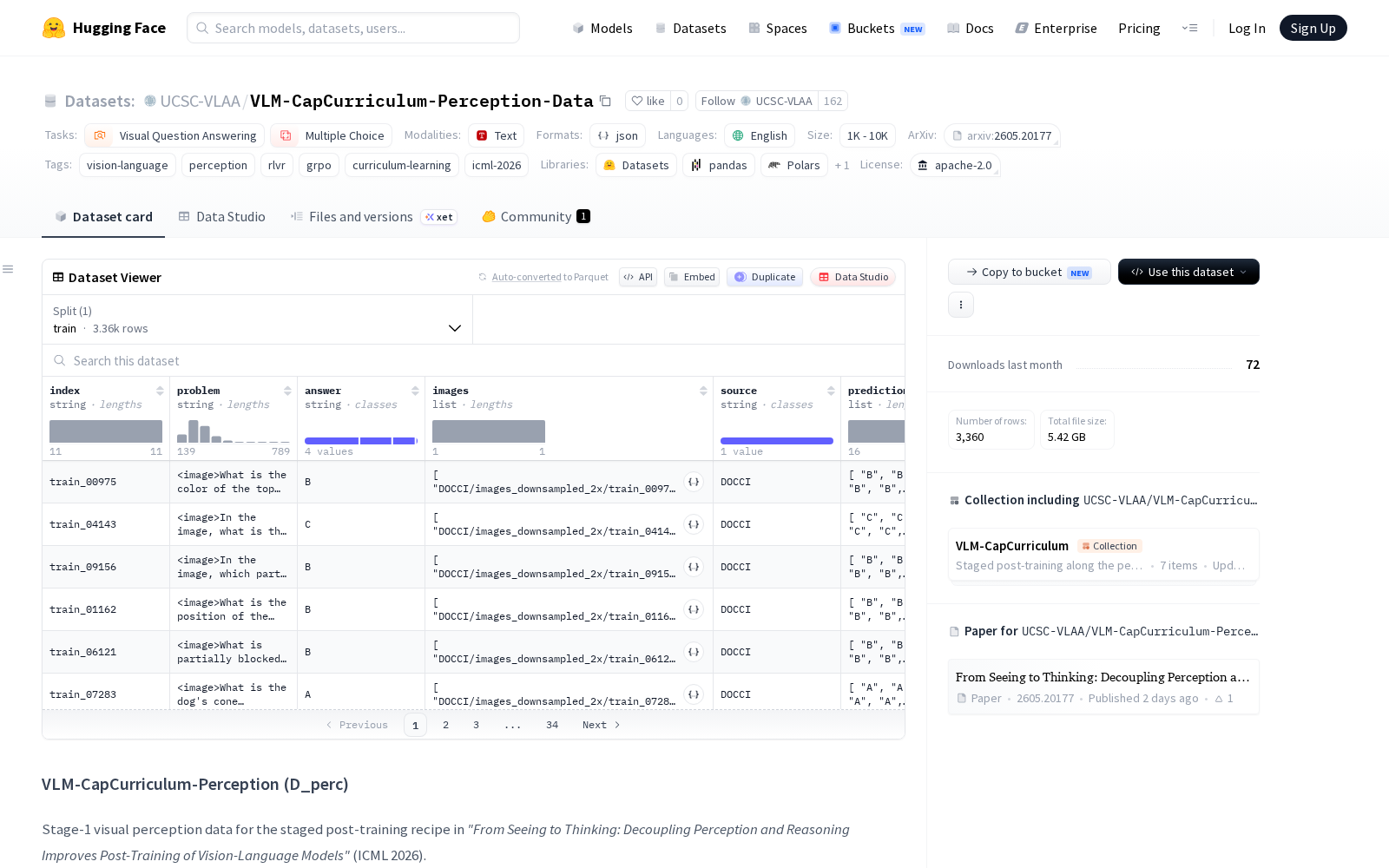
据公开信息显示,该数据集的每个样本均包含对应图像、问题、标准答案三个核心字段,同时标注了基于通义千问Qwen3-VL-8B-Instruct模型16次推理结果计算得出的预测值、正确性标识和核心的通过率(pass_rate)指标。其中pass_rate作为样本的难度信号,支持研究者按照难度升序(困难优先)或降序(简单优先)对数据集进行排序,从而开展基于模型能力与样本难度匹配的课程学习实验,探索更高效的VLM训练策略。规模方面,该数据集共包含3360个训练样本,所有图像均源自DOCCI数据集并做2倍下采样处理,总计覆盖14847个图像文件。
从应用场景来看,该数据集首先可用于VLM的感知能力精准评估,帮助研究者快速定位模型的视觉感知短板,比如细粒度物体识别、空间关系判断、微小特征捕捉、多物体属性区分等能力的不足,无需受到推理能力的干扰;其次可作为VLM分阶段后训练的第一阶段(感知训练)专用数据,搭配实验室同步推出的姊妹数据集TextReasoning(文本推理)、VisualReasoning(视觉推理),即可构成完整的感知-推理解耦训练流程,大幅提升VLM后训练的效率与效果;此外,自带的难度标签也使其成为课程学习领域的核心研究数据,支撑相关领域学者探索不同训练策略对VLM能力提升的影响。
作为AI训练数据要素市场中少有的多模态大模型专项能力训练数据集,该数据集的发布不仅填补了VLM感知能力专项训练数据的空白,也为多模态大模型的精细化训练、标准化评估提供了新的可行路径,对于推动多模态大模型的落地应用、完善AI训练数据供给体系均具有重要的参考价值。
查看VLM-CapCurriculum-Perception-Data
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)