

当前生成式AI正从通用能力向垂直场景落地快速演进,强化学习、检索增强生成(RAG)技术已成为提升模型知识准确性、复杂任务执行能力的核心路径,而标准化、可复现的垂直场景训练评估数据集,始终是制约相关技术迭代效率的核心瓶颈之一。作为全球知名的开源AI数据集运营机构,LAION eV此前推出的LAION-5B等数据集曾为生成式AI的技术爆发提供了核心数据支撑,此次推出新数据集正是瞄准强化学习在知识处理场景的需求缺口。
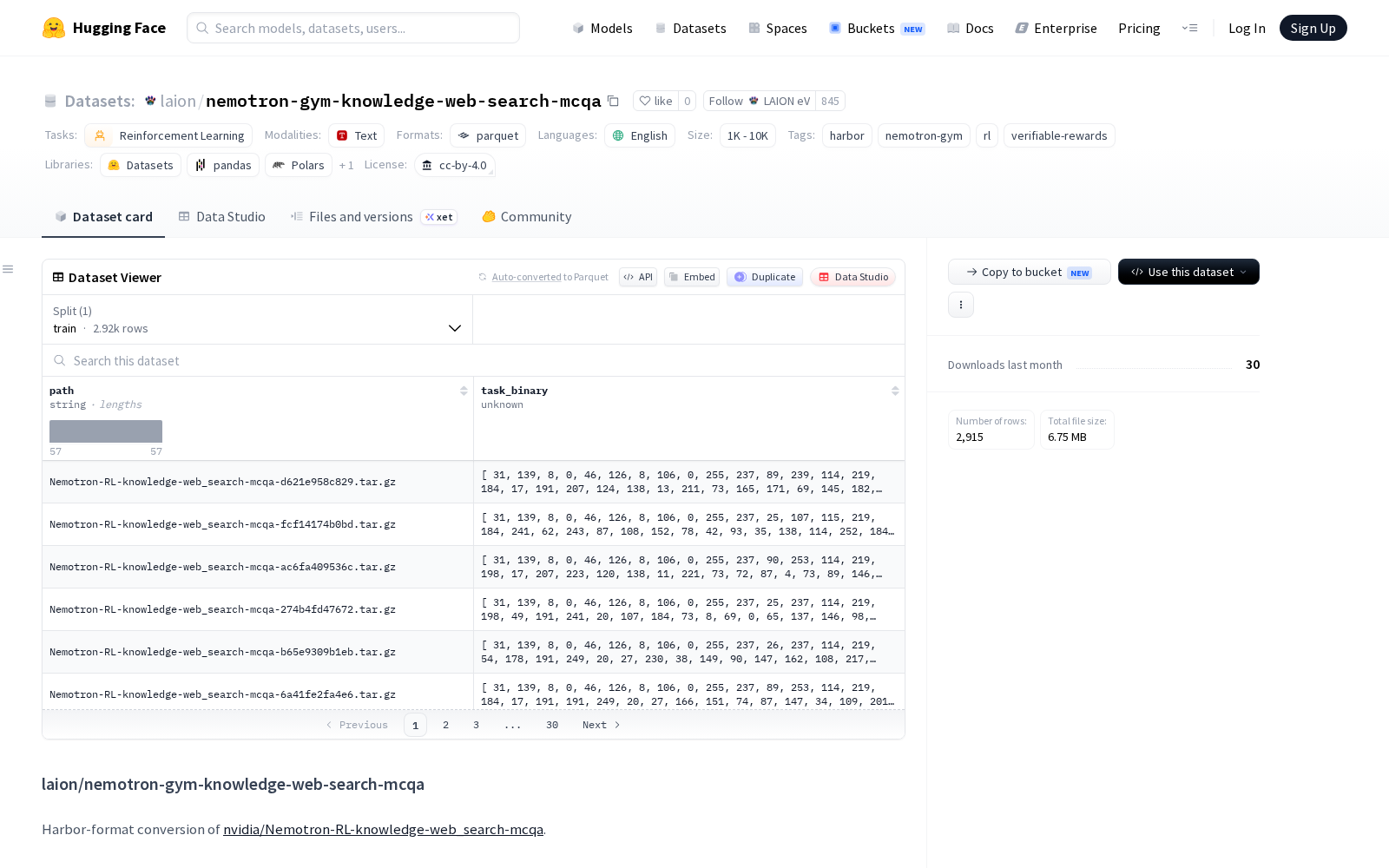
2026年5月16日,LAION eV正式在HuggingFace平台首发nemotron-gym-knowledge-web-search-mcqa数据集,该数据集为nvidia/Nemotron-RL-knowledge-web_search-mcqa的Harbor格式转换版本,定位强化学习垂直任务数据集,核心覆盖知识问答与网络搜索两大训练场景。
本次发布的数据集样本规模在1000到10000之间,语言为英语,每个数据行包含两个核心字段:path为确定性短ID字符串,格式为
为了保障训练过程的安全稳定,本次数据集的转换过程设置了严格的安全校验机制,确保数据集内容不会直接插入到shell、Python或Dockerfile源代码中,所有参数值均通过JSON文件传递,同时对所有路径进行了严格验证和字符过滤,避免恶意代码注入风险。此外,整个任务包采用确定性设计,支持不同环境下的可重复运行,为学术研究、企业研发中的对比实验提供了统一的基准载体。
从应用方向来看,该数据集可广泛应用于强化学习模型的训练与评估环节,尤其是涉及知识检索、多项选择问答的垂直任务:包括检索增强生成(RAG)系统的知识召回准确率评估、大模型知识问答模块的RLHF(人类反馈强化学习)训练、智能体自主网络搜索能力的训练与验证、AI多轮问答系统的答案准确性测试等典型场景。对于整个AI产业而言,这类标准化垂直训练数据集的开源开放,不仅能够降低相关领域的研发门槛,减少企业和科研机构的数据集建设成本,也为不同技术路线的效果对比提供了统一基准,有助于推动强化学习在知识处理、智能搜索等领域的落地迭代,进一步丰富AI训练数据要素的供给体系。
查看nemotron-gym-knowledge-web-search-mcqa
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)