

作为德国联邦政府下属的专业国际合作机构,Deutsche Gesellschaft für internationale Zusammenarbeit(简称GIZ,德国国际合作机构)长期在全球范围内推动数字公共产品建设、开源AI基础设施普惠,此次发布的sample_datatset是其在自然语言处理(NLP)领域的最新开源成果,瞄准当前生成式AI落地过程中评测标准不统一的行业痛点。当前查询重写、语义检索已成为RAG(检索增强生成)、智能问答、企业知识库、公开信息检索等场景的核心技术环节,但其评测环节长期缺乏标准化公共数据集:不同厂商自研测试集的场景覆盖度、数据质量参差不齐,不同算法、不同模型的效果横向对比难度高,中小团队更是缺乏足够资源搭建合规、全面的评测基准,一定程度上制约了NLP应用的规模化落地。
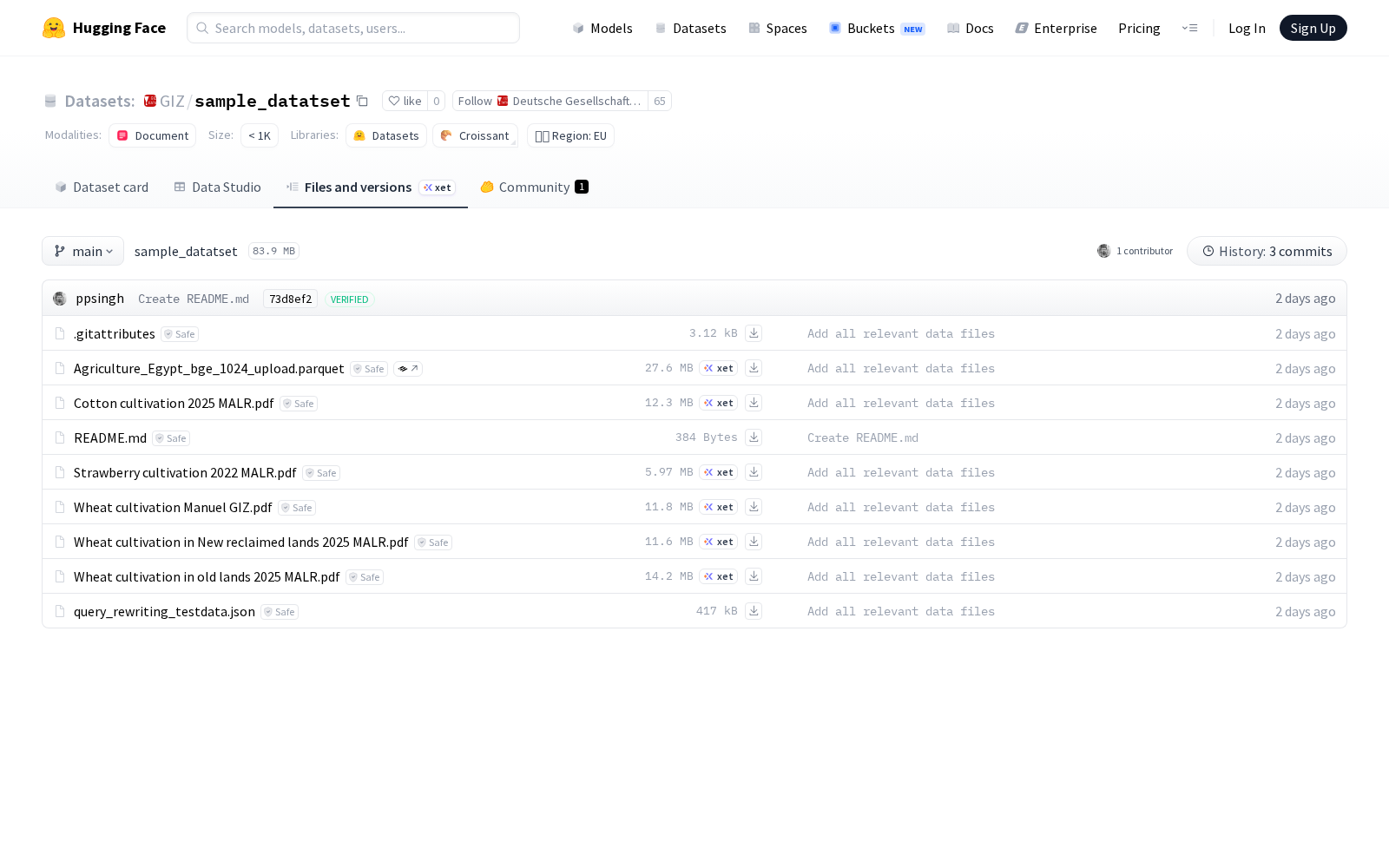
本次发布的sample_datatset数据集核心面向查询重写(query-rewriting)任务开发与语义检索系统评估打造,整体由三大模块构成,覆盖从原始数据溯源到评测基准搭建的全流程需求:1)5个原始PDF文件,可支持研究人员校验文本提取效果,保障数据的可追溯性;2)一个parquet格式结构化文件,其中包含从上述5个PDF及额外30个PDF中提取的标准化文本块(chunks),文件中同步预置了每个文本块使用当前主流多语言嵌入模型bge-m3生成的嵌入向量、对应元数据、原始文本内容以及唯一ID列,预生成的嵌入向量可免去开发者重复计算的算力成本,直接调用开展召回测试;3)一个testdata格式的JSON文件,明确定义了第一版查询重写任务涵盖的所有测试场景,每个场景包含对应查询问题、关联的文本块ID以及查询重写的预期行为,为算法效果评估提供了统一的判断标准。整个数据集的核心资产为parquet文件中的文本块及其预生成嵌入表示,JSON文件则提供了针对性的任务定义和评估基准,二者结合可直接支撑算法开发、效果评测等多元需求。
从应用场景来看,该数据集可广泛应用于多个NLP落地场景:企业在开发RAG系统时,可基于该数据集测试不同查询重写策略的召回准确率,优化RAG系统的回答质量;语义检索服务商可将其作为标准化benchmark,横向对比不同版本检索系统的效果,避免自研测试集带来的偏差;学术研究人员可基于该统一数据集开展查询重写算法创新,提升不同研究成果的可比性;针对垂类场景的大语言模型也可基于该数据集的测试场景开展微调,提升用户query的理解能力。作为开源公共AI数据集,sample_datatset的发布也为数据要素市场中的公共AI资源建设提供了参考,标准化的评测类数据集是AI产业发展的核心公共基础设施,这类开源成果的落地,将有效降低中小团队的开发门槛,推动NLP应用的标准化、规范化发展。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)