

随着大模型技术向产业场景渗透,自然语言智能体的任务执行能力、强化学习的指令对齐效果已成为AI领域的核心研发方向,但长期以来,适配强化学习训练的专用数据集普遍存在环境配置不统一、安全校验缺失、训练结果不可复现等行业痛点,制约了相关技术的规模化落地。曾推出支撑Stable Diffusion训练的大规模开源图文数据集的全球知名AI数据开源组织LAION eV,近日正式上线其最新数据集产品nemotron-gym-instruction-following,为相关前沿研发提供了标准化的数据基础设施。
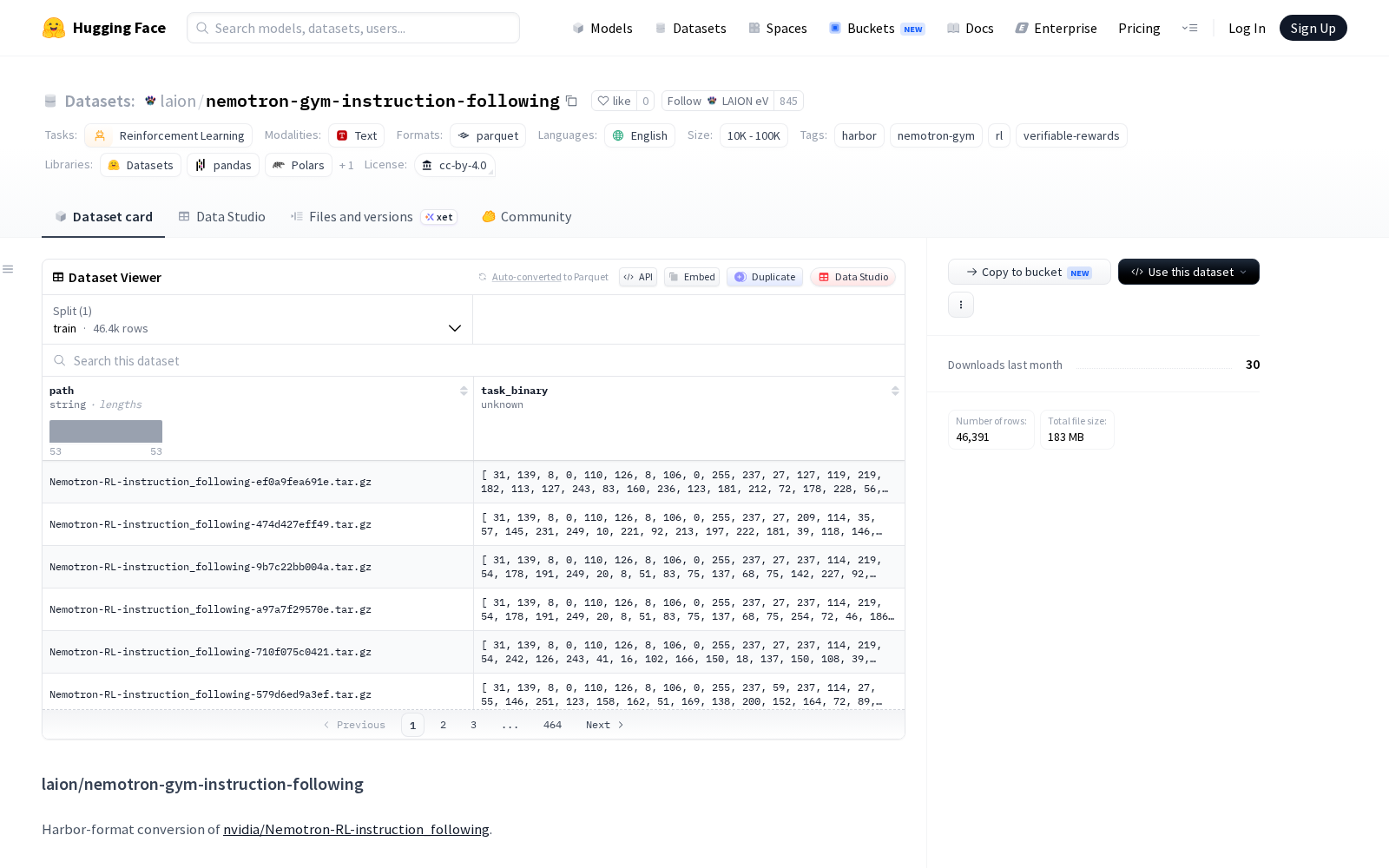
据官方披露,本次发布的nemotron-gym-instruction-following是NVIDIA官方NeMo-Gym集合中nvidia/Nemotron-RL-instruction_following数据集的Harbor格式转换版本,专门面向强化学习任务设计,尤其适配指令遵循场景的训练与评估需求,样本规模处于1万到10万区间,全部为英语语料。每个数据样本包含两个核心字段:path(确定性短ID字符串)和task_binary(包含完整Harbor任务的gzip压缩tar二进制数据)。
其采用的标准Harbor任务布局覆盖了智能体训练的全流程需求:其中instruction.md为向智能体公开的任务提示指令,基于python:3.11-slim-bookworm定制的环境Dockerfile统一了运行环境,避免不同开发者本地配置差异导致的训练结果偏差;验证器入口脚本test.sh、实现文件verifier.py及基准验证数据verifier_data.json可实现智能体任务完成效果的自动化校验;metadata.json可溯源数据来源,task.toml为标准化Harbor任务配置文件,大幅降低了开发者的适配成本。
本次格式转换过程重点强化了安全与可复现能力:数据集内容不会直接插值到shell、Python或Dockerfile源代码中,所有参数均通过JSON文件传递,避免了代码注入风险;基础镜像版本固定,文本字段全部经过控制字符清理与长度限制,tarball路径经过防遍历攻击验证,且tarball生成过程具备确定性,彻底解决了传统强化学习训练数据中常见的结果不可复现问题。其配套的IFEval风格验证器可自动完成段落、单词、内容合规性、格式等多维度校验,大幅降低了人工标注与评估成本。
该数据集可广泛应用于强化学习指令对齐训练、自然语言智能体任务规划与执行能力评估、代码生成智能体效果测试、多智能体协作指令分发验证等多个前沿研发场景,用户可直接通过Hugging Face datasets库加载数据,提取单个任务后即可在Harbor环境中运行。作为AI训练数据细分领域的最新成果,该数据集既适配NVIDIA NeMo生态的研发需求,也采用了通用开放的Harbor格式,有助于降低中小研发团队的强化学习智能体训练门槛,为AI训练数据的标准化、安全化建设提供了可参考的实践路径,也将进一步推动自然语言智能体技术从实验室走向产业落地。
查看nemotron-gym-instruction-following
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)