

随着多模态大模型技术的快速迭代,语音作为核心交互入口的价值持续凸显,其中离散语音标记技术因可与大语言模型的Token体系天然适配,成为当前语音AI领域的研发热点。但长期以来,行业内缺乏经过标准化预处理的高质量离散语音标记数据集,多数研发团队需要自行完成音频采集、降噪、量化编码等全流程预处理工作,占用大量研发资源,也抬高了中小团队的准入门槛。
本次Trelis发布的libritts-snac-tokens正是瞄准这一行业需求推出的语音合成标记数据集,其基于开源领域认可度极高的LibriTTS-R多说话人英语语音语料库构建,核心内容是将原始24kHz音频信号,通过hubertsiuzdak/snac_24khz分层残差向量量化(RVQ)编解码器进行编码,生成标准化的离散标记序列。编码过程采用Orpheus风格的交错模式:每个音频帧(1/12秒)对应7个标记,分别来自三个量化层级(L0, L1, L2),从而形成平坦的84帧/秒的标记流,整个标记词汇表大小为12288,其中L0、L1、L2三个层级各占4096个条目。
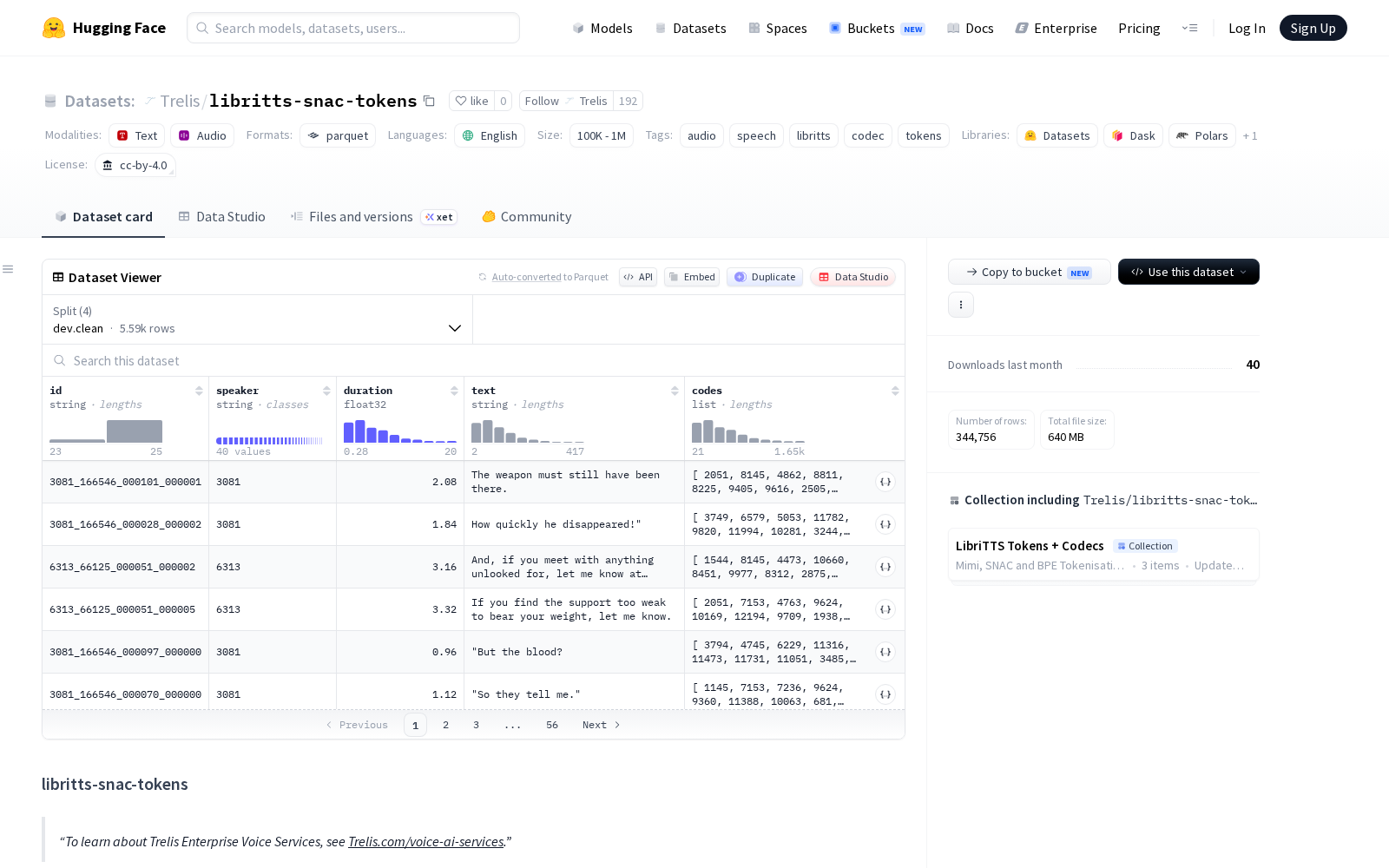
数据集的划分完全遵循源LibriTTS-R的划分规则,并经过parler-tts过滤,包含train.clean.100、train.clean.360、train.other.500和dev.clean四个子集,总计约538小时的音频内容。每个数据样本(对应单条话语)包含唯一标识符 `id`、说话人ID `speaker`、音频时长(秒)`duration`、规范化文本 `text` 以及核心的编解码器标记序列 `codes` 五个字段,可直接导入模型训练流程使用。
从应用场景来看,该数据集适用于所有需要高质量离散语音表示的研发场景:在语音合成领域,可支撑实时语音生成、多说话人语音克隆、个性化语音助手、有声书自动生成等产品的模型训练;在语音表示学习领域,可用于低资源语音识别预训练、语音特征提取模型优化、语音情感/意图识别模型训练等研发任务;此外,标准化的离散语音标记数据也可为语音内容审核、语音数字水印、语音隐写检测等安全类应用提供训练素材。该数据集采用CC-BY-4.0开源许可证,与源数据集协议一致,支持商业使用,可大幅降低研发团队的预处理成本,缩短产品迭代周期,也为语音AI领域的技术复用、成果落地提供了公共数据要素支撑。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)