

随着数字人文交叉学科的快速发展,结构化、标注化的历史文本语料缺口成为制约相关研究与应用落地的核心瓶颈——尤其是近代以前的非通用语种历史文献,普遍存在数字化程度低、标注成本高、可复用性差等问题。作为北欧顶尖的人文计算研究机构,奥胡斯人文计算中心(Center for Humanities Computing Aarhus)长期深耕历史文化资源的数字化治理与开放共享,本次上线的全新数据集为这一领域带来了重要的公共资源补充。
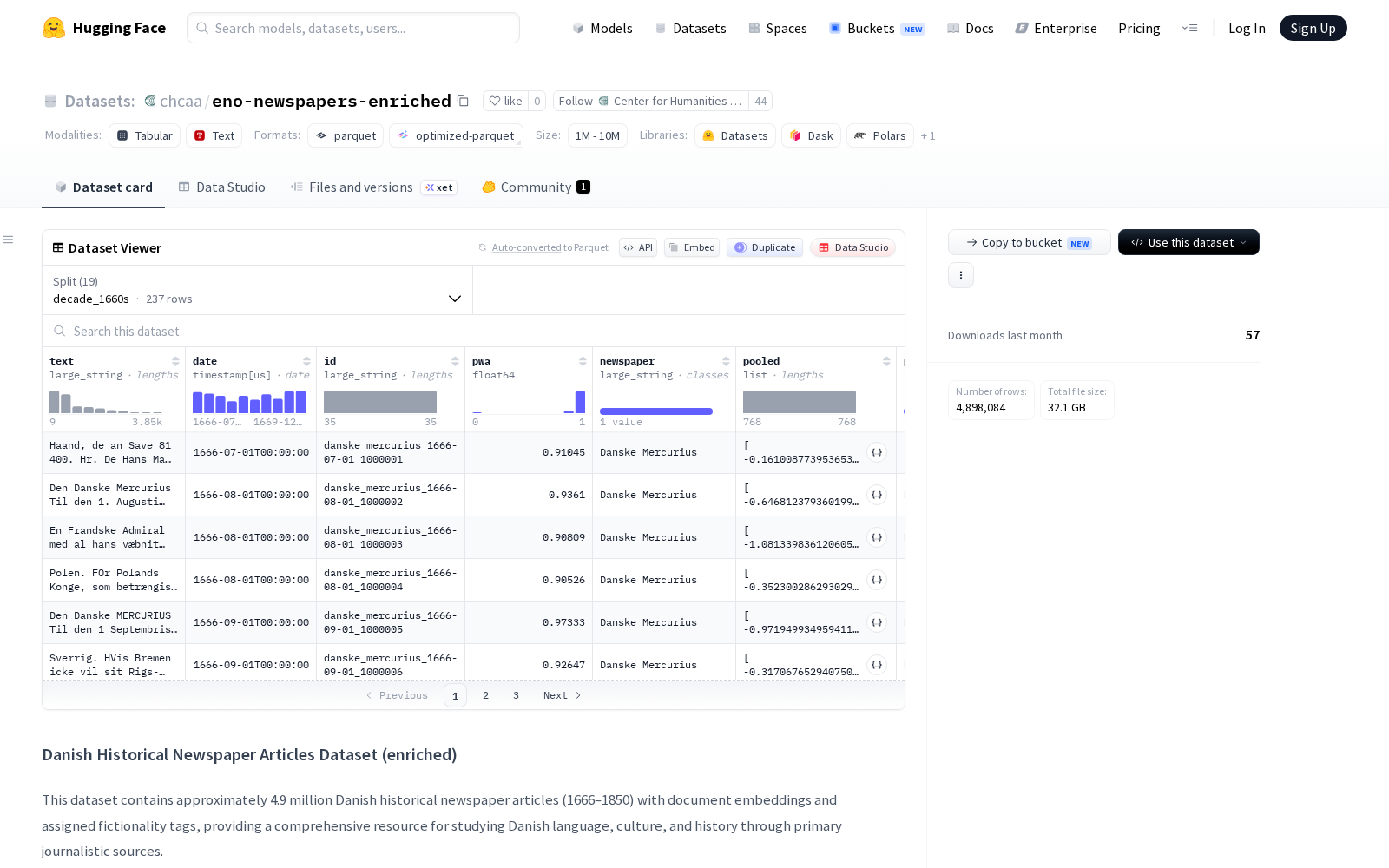
本次发布的eno-newspapers-enriched全称为Danish Historical Newspaper Articles Dataset (enriched),是目前公开领域规模最大的标注版丹麦近代历史报纸语料库,共收录1666年至1850年间28种丹麦-挪威时期历史报纸、期刊的数字化内容,总文章数约4,898,084篇,未压缩数据集大小约33.7 GB,下载大小约25.1 GB,采用丹麦语Parquet文件格式存储,方便研究人员快速调用与处理。数据集不仅提供完整的文章文本内容,还配套了多维度结构化元数据,极大降低了后续研究的数据预处理成本。
数据集包含10余项核心字段,覆盖内容、属性、标注结果三大维度:基础属性字段包括唯一文章标识符id、发布日期date、出版年份year、出版年代decade、所属报纸标题newspaper;内容字段包括完整文章文本text、概率加权属性pwa;预计算资源字段包括采用Old_News_Segmentation_SBERT_V0.1模型生成的语义嵌入向量pooled,可直接用于语义相似度计算、文本聚类等任务,无需用户二次训练;自动标注字段包括predicted_category(国内新闻、国际新闻、广告、副文本等内容类别)、fictionality_tag(小说/非小说虚构性标签)、fiction_prob/non_fiction_prob(对应标签的置信概率)。为了适配不同时间跨度的研究需求,数据集还按年代(decade)进行分片存储,比如decade_1660s、decade_1670s等,研究人员可按需加载对应时间段的语料,无需处理全量数据。
为保障自动标注结果的可靠性,研究团队采用了成熟的分类模型训练与验证流程:内容类别标签通过在Old_News模型嵌入上训练的Logistic回归分类器生成,在广告、国内新闻、国际新闻三类核心标签上的F1分数达到0.93–0.97,标注精度接近人工标注水平;虚构性标签同样基于Old_News嵌入的Logistic回归分类器生成,通过分层组k折交叉验证验证性能,在小说、非小说类别上的精确率/召回率达到0.88–0.89,概率校准Brier分数仅为0.024,标注结果置信度极高,最终全量数据中约有77,513篇文章(占比约1.58%)被分类为小说类内容。
作为经过富集标注的高质量历史语料,该数据集的应用场景覆盖学术研究与产业创新多个方向:在基础研究领域,可用于丹麦语言演化追踪、17-19世纪北欧社会史/传媒史研究、近代公共舆论演变分析等数字人文课题;在技术研究领域,可支撑历史语言分析、低资源语种文本分类、跨时代语义相似度计算等自然语言处理任务的模型训练与效果验证;在创新应用领域,可用于开发历史事件检索工具、近代报刊内容可视化平台、历史文化科普产品等落地场景。
研究团队也同步公开了数据集的已知局限性,提醒用户在使用过程中注意规避:受近代印刷质量、纸张退化、OCR识别技术限制,部分文本可能存在识别错误;文章边界识别误差可能导致少量文章出现合并、拆分问题;内容本身反映了丹挪时期的社会观点与偏见,可能包含不符合当下价值观的表述;数字化资源未覆盖该时间段的所有报纸,现存样本也可能存在地区、政治立场、社会阶层的代表性偏差;丹麦语拼写、正字法随时间演变,不同年代的文本存在语言差异。该数据集由Alie Lassche、Pascale Feldkamp和Johan Heinsen策划,原始数字化工作由Johan Heinsen和Camilla Bøgeskov在ENO项目下完成。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)