

作为全球首个专注人工智能领域的研究生级研究型大学,穆罕默德·本·扎耶德人工智能大学(MBZUAI)长期深耕多语言自然语言处理(NLP)领域,是阿拉伯语AI技术研究的全球核心标杆机构。当前全球多语言大模型产业快速发展,但阿拉伯语作为覆盖全球22个国家、超过4亿使用者的通用语言,始终缺乏标准化的句子分割基准数据集,大量标点不规范的社交媒体文本、OCR识别文档、语音转写内容的分句准确率不足60%,直接制约了阿拉伯语NLP应用的落地效率。
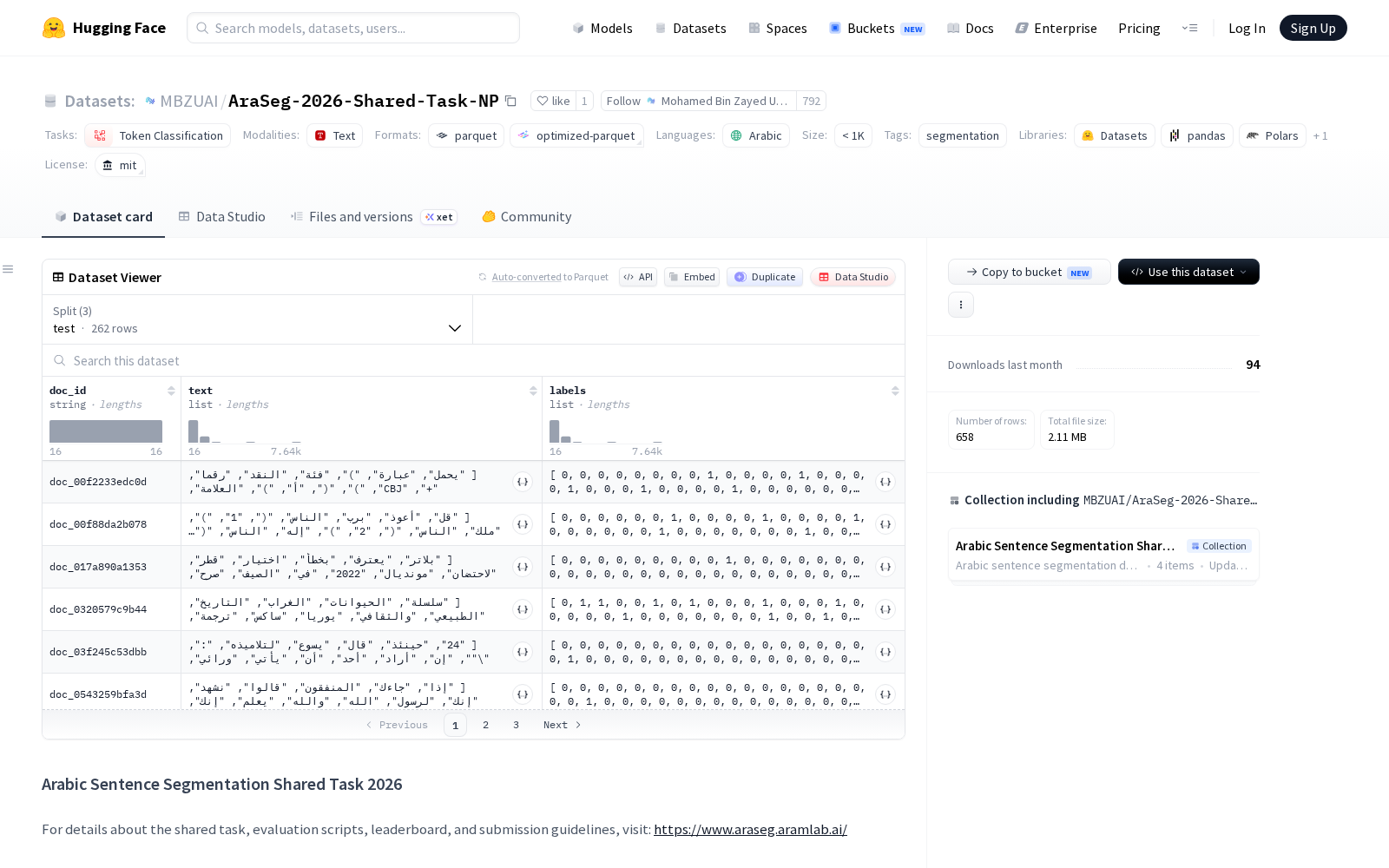
此次MBZUAI发布的AraSeg-2026-Shared-Task-NP数据集,正是全球首个用于阿拉伯语句子分割的综合基准数据集,核心瞄准现代标准阿拉伯语(MSA)在标点不一致、缺失或嘈杂环境下的句子分割研究痛点。该数据集包含从多样来源和体裁收集的手动标注文档,支持跨不同写作风格和领域的鲁棒评估。数据集同时提供AraSeg-NP变体,其中移除了段落边界,可适配无格式标注的纯文本分句需求。在结构上,每个数据实例包括唯一文档标识符(doc_id)、以分词token列表形式表示的文本(text),以及token级句子边界标签(labels),其中标签1表示当前token后跟随句子边界,0表示无边界。数据集分为训练集(174个文档,含10,657个句子和124K词)、开发集(222个文档,含12,985个句子和159K词)和测试集(262个文档,含12,509个句子和154K词),总大小约8.6MB。任务定义为二元token分类,即给定token序列,预测每个token后是否有句子边界。评估采用边界级指标,包括精确率、召回率和F1值,在文档级别计算并跨语料库平均,可统一衡量不同分句模型的性能差异。
从应用潜力来看,该数据集可广泛应用于多个阿拉伯语数字化场景:在大模型预训练环节,高质量的句子分割标注可大幅提升阿拉伯语语料的预处理效率,优化大模型的阿拉伯语语义理解能力;在内容治理领域,可支撑社交媒体、短视频字幕等非规范文本的语义解析,提升有害内容识别的准确率;在政务、司法数字化场景中,可实现阿拉伯语公文、法律卷宗的自动结构化,降低人工信息提取成本;此外也可为跨境电商阿拉伯语智能客服、伊斯兰古籍数字化整理等场景提供基础技术支撑。
业内人士指出,基准数据集是AI产业的核心公共基础设施,低资源语言的数据集供给不足是全球AI普惠发展的核心短板之一。此次AraSeg-2026数据集的开源发布,不仅填补了阿拉伯语句子分割领域的基准空白,也为其他小语种同类数据集的建设提供了可参考的框架,对推动中东、北非地区的数字经济发展与AI技术落地具有重要意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)