

随着全球AI技术向多语种、区域化落地推进,小语种高质量标注数据的供给缺口已成为制约区域AI产业发展的核心瓶颈之一。阿拉伯语作为全球22个国家的官方语言、覆盖超4亿使用人口的大语种,相关自然语言处理(NLP)任务长期面临标注数据集数量少、标准化程度低、开源供给不足的问题,限制了中东、北非等地区的数字化服务落地与AI技术普惠。
本次发布数据集的穆罕默德·本·扎耶德人工智能大学(Mohamed Bin Zayed University of Artificial Intelligence,简称MBZUAI)是阿联酋重点建设的全球顶尖AI研究型高校,也是中东地区首所专注人工智能领域的高等教育与科研机构,长期聚焦多语种AI技术研发、阿拉伯语AI标准制定与产业落地,在区域AI创新生态中具备核心影响力。
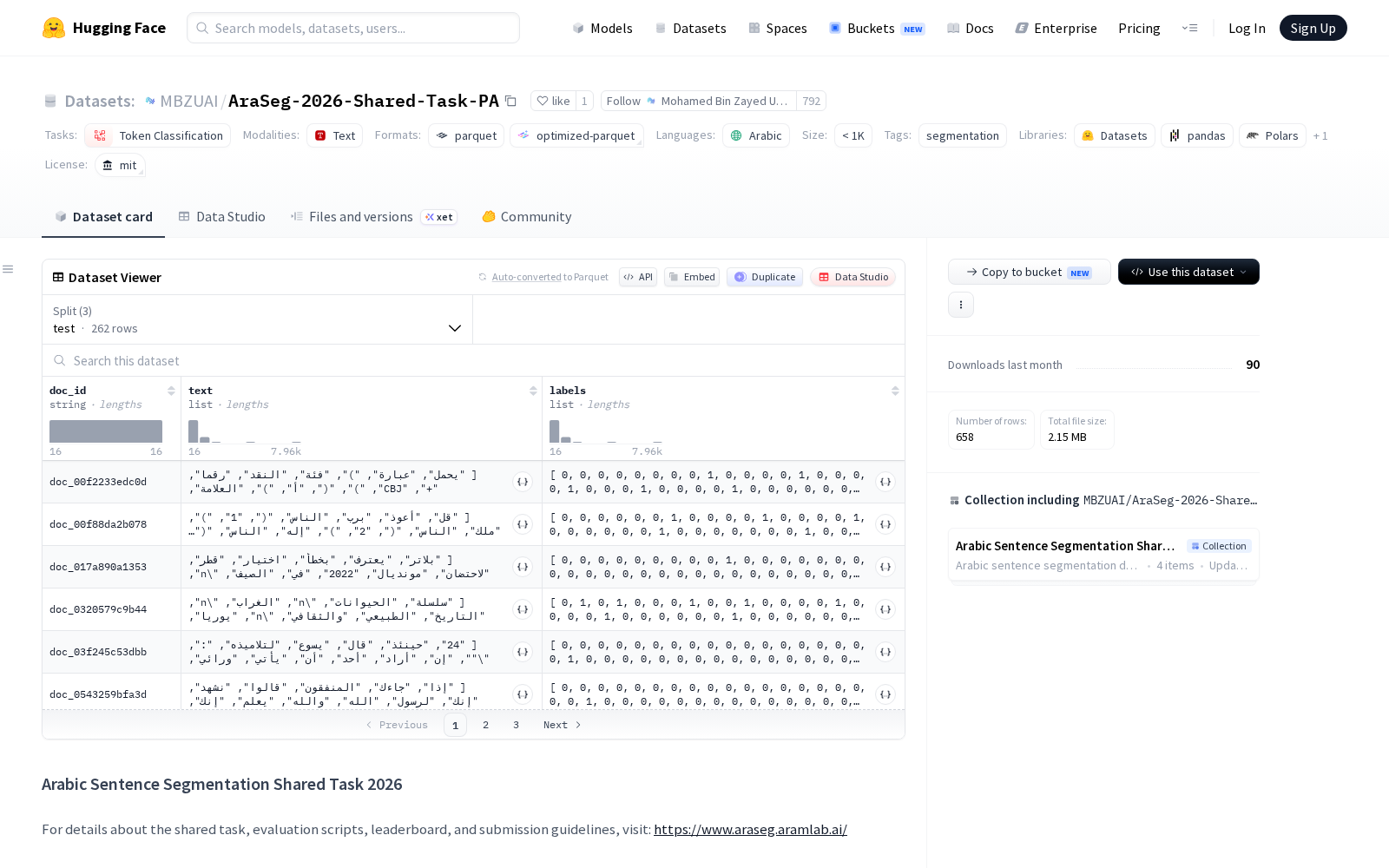
2026年5月18日,MBZUAI正式在HuggingFace平台首发开源AraSeg-2026-Shared-Task-Pnx-PA数据集,该数据集采用商业友好的MIT许可证,开发者可免费用于学术研究与商业开发场景。数据集总大小约为9.1 MB,共分为三个划分:训练样本(train_sampled,3,903个示例)、开发集(dev,5,066个示例)和测试集(test,5,025个示例),总计近1.4万条标注样本。每个示例由四个结构化字段组成:doc_id(文档标识符,字符串类型)、paragraph_id(段落标识符,整型)、text(文本内容,字符串列表)和labels(标签,整型列表),数据组织规范适配各类主流NLP训练框架,可直接用于文档或段落级别的分类、序列标注或信息提取等任务。
从应用价值来看,该数据集可支撑的典型场景涵盖多个领域:在公共服务领域,可用于阿拉伯语政务文本的智能分类、居民诉求的意图识别,提升政务服务响应效率;在文化领域,可支撑阿拉伯语历史典籍的数字化标注、语义检索,助力文化遗产的数字化保护与传播;在商业领域,可用于跨境电商阿拉伯语用户评论的情感分析、客服对话的实体提取,提升出海企业的区域用户服务能力;在社会治理领域,可用于阿拉伯语舆情的关键信息抽取、风险内容识别,助力区域网络空间治理。
该数据集的开源,不仅填补了阿拉伯语NLP领域高质量标准化标注数据集的供给缺口,也为全球阿拉伯语NLP技术的基准测试提供了统一的参考数据集,对推动多语种AI技术均衡发展、完善全球数据要素市场的多语种数据供给体系具备积极意义。
查看AraSeg-2026-Shared-Task-Pnx-PA
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)