

随着大语言模型在企业专属客服、数字人交互、垂直领域AI助手、虚拟IP运营等场景的规模化落地,模型输出的身份一致性、角色遵循能力已经成为区别通用大模型与场景化模型的核心指标,也直接决定了C端用户交互体验与B端业务合规性。但长期以来,行业针对大模型“身份遵循”能力的强化学习评估缺乏统一的标准化数据集,不同厂商自定义的测试规则不具备横向可比性,且多数评估工具仅能适配完成过特定身份微调的模型,无法覆盖基础大模型的测试需求,大幅抬高了全行业的身份对齐评估门槛。
作为全球领先的开源AI数据集建设机构,LAION eV此前推出的LAION-5B等大规模多模态数据集曾支撑了Stable Diffusion等多款现象级AI模型的训练,在AI数据资源领域拥有极高的行业认可度。近日LAION eV正式发布的nemotron-gym-identity-following-v2数据集,正是瞄准上述行业痛点推出的专项评估工具,该数据集已于2026年5月18日首发上线HuggingFace平台。
据官方介绍,本次发布的v2数据集是‘nvidia/Nemotron-RL-Identity-Following-v1’数据集的Harbor格式转换版本,属于NVIDIA NeMo-Gym集合的一部分,专为强化学习任务设计,核心用于评估语言模型在“身份遵循”维度的能力,样本规模处于1万到10万区间。与v1版本相比,v2版本完成了两项关键迭代,大幅提升了工具的适配性与可用性:首先,数据集明确解析评估标准并添加了指令前导,可直接向被测试智能体告知目标身份(例如“你是Nemotron 3 Super,一个由NVIDIA训练的模型”)以及目标响应语言,这使得原本仅能适配已完成特定身份微调模型的评估流程,现在也可直接用于普通基础模型的单轮测试(single-turn rollouts),无需提前对基础模型做额外适配,大幅降低了评估前置成本。其次,v2版本新增了[verifier.env]配置声明,支持Harbor在运行时将主机环境中的OPENAI_API_KEY传递到验证器沙箱(verifier sandbox)中,彻底解决了v1版本中基于littellm的评估法官(judge)因缺少凭证而在每次试验中都失败的问题,评估流程的可用性提升至100%。
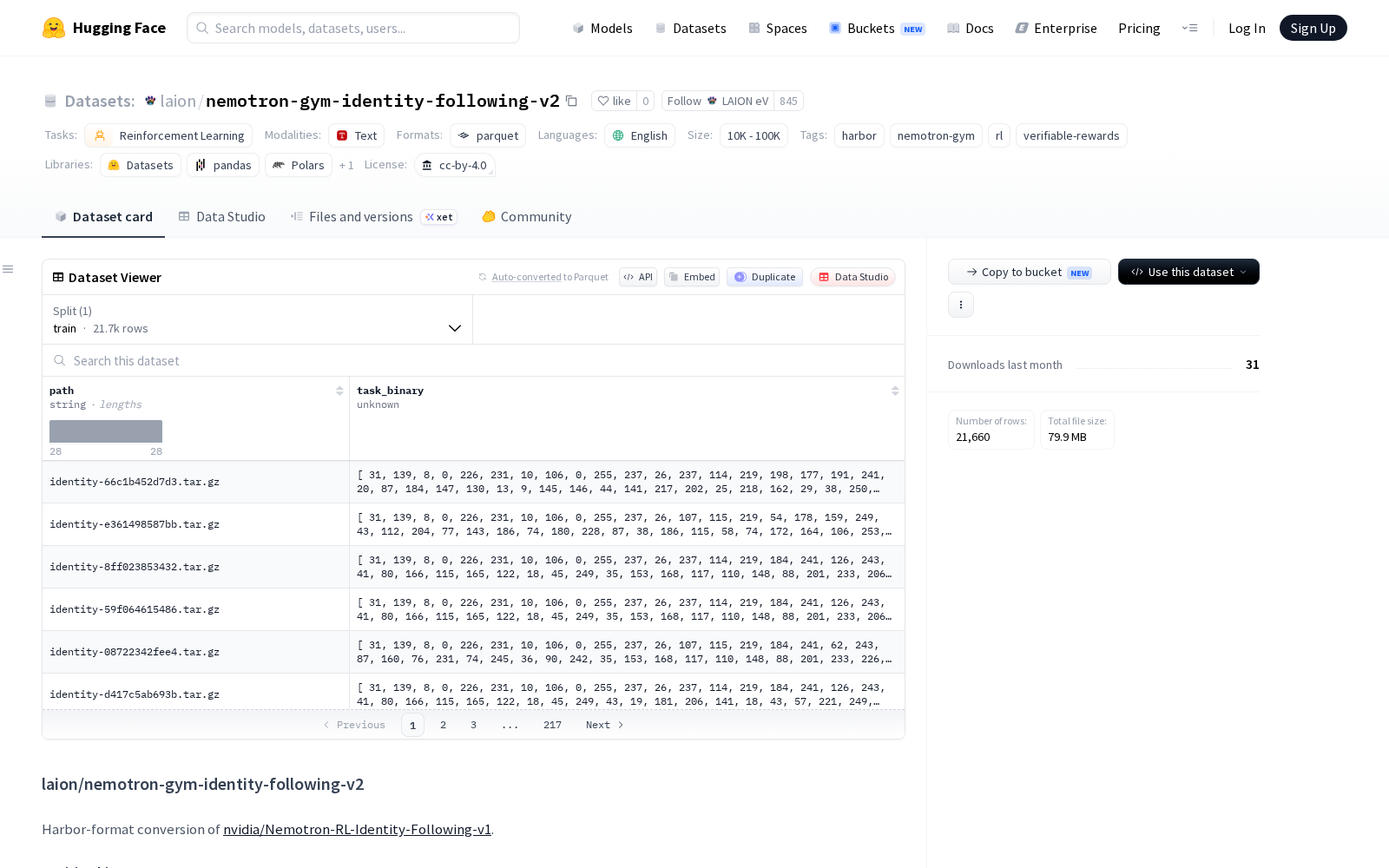
从数据集结构来看,该数据集的每一行包含两个字段:一个字符串类型的确定性短ID(‘id’),以及一个二进制类型的gzipped tar包(‘task’),tar包内包含遵循Harbor任务布局的完整评估任务。用户使用此数据集运行Harbor评估时,仅需要在主机上设置OPENAI_API_KEY环境变量即可启动测试,也可根据自身需求指定JUDGE_MODEL(默认使用‘openai/gpt-4o-mini’)。
从应用场景来看,该数据集可覆盖产业端与学术端的多类需求:在大模型研发环节,厂商可将其作为RLHF、RLAIF等强化学习对齐流程的标准评估工具,验证模型身份对齐的效果,保障垂类场景模型的输出符合预设角色要求;第三方测评机构可将其作为大模型身份一致性能力的基准测试集,输出的评估结果具备行业横向可比性,助力建立统一的大模型能力评估标尺;学术研究领域可依托该数据集开展大模型身份鲁棒性、prompt注入防护、角色记忆机制等方向的研究;垂直场景应用开发团队,例如数字人、AI助教、智能客服开发团队,可使用该数据集快速验证模型的身份匹配度,缩短产品上线前的测试周期。目前该数据集已广泛适用于研究如何通过强化学习来对齐或微调语言模型,使其输出符合特定预设身份或角色,并支持可验证的奖励(verifiable rewards)机制。
查看nemotron-gym-identity-following-v2
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)