

随着AI技术向工业设计领域的深度渗透,硬件研发自动化成为电子信息产业降本提效的核心方向之一。作为所有电子设备的核心载体,PCB(印刷电路板)的传统设计流程高度依赖资深工程师的经验积累,从需求拆解到原理图绘制、验证的周期长、门槛高,中小硬件团队的研发成本长期居高不下。大语言模型的爆发为自然语言直接驱动硬件生成带来了可能性,但垂直场景下高质量的对齐训练数据缺失,一直是制约相关技术落地的核心瓶颈。
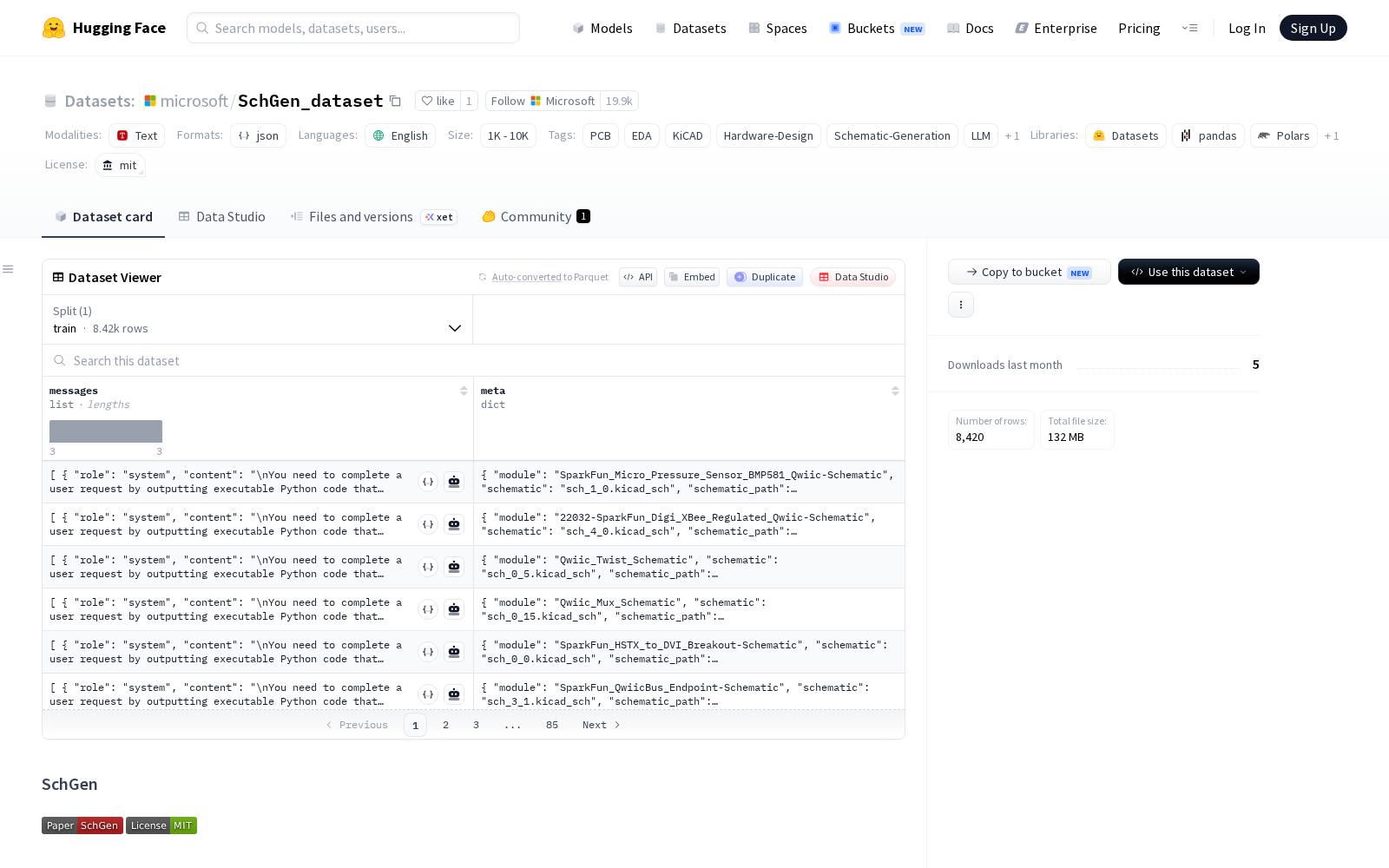
本次微软发布的SchGen_dataset,正是瞄准这一行业空白打造的专用训练数据集,核心定位为LLM驱动PCB原理图生成研究提供标准化数据底座。数据集共包含约8420对自然语言硬件设计请求与对应Python格式的原理图生成代码,生成的Python代码可直接渲染为KiCad格式的原理图设计文件,完整打通了从自然语言需求到可落地硬件设计文件的链路。该数据集的构建工作于2025年8月至9月完成,采用多阶段校验流程保障数据质量:首先由GPT-5基于开源硬件参考生成草稿原理图设计,随后通过人工注释、校验环节确保KiCad格式原理图的电气连接正确性与可执行性,最终再由GPT-5基于最终定稿的原理图反向合成对应的自然语言用户请求。值得注意的是,尽管草稿阶段参考了采用CC BY-SA 4.0许可的SparkFun原理图等开源硬件资源,但最终发布的数据集未直接包含任何原始开源设计内容,避免了版权风险。
从应用特性来看,SchGen_dataset具备四大核心优势:一是完全兼容KiCad生态,生成的Python代码可直接执行并输出有效的原理图文件,无需二次转换;二是实现了自然语言需求到硬件设计的对齐,可支撑从用户文字需求直接生成PCB原理图的相关研究;三是采用程序化原理图构建API作为数据载体,而非原始的原理图文件,更适配大语言模型的训练逻辑;四是明确面向研究场景设计,可广泛应用于LLM微调、硬件生成能力基准测试、AI辅助PCB设计工作流程探索等多个方向。从潜在应用价值来看,基于该数据集微调后的大语言模型,未来可实现硬件工程师仅通过自然语言描述功能需求,即可自动生成符合规范的PCB原理图,大幅降低中小硬件团队的研发门槛;也可作为行业通用的基准测试工具,统一不同AI硬件生成模型的能力评估标准,推动整个领域的技术迭代。
为验证数据集的可用性,微软团队采用三类核心指标对数据集效果进行了评估:一是有效电路指标,衡量生成代码是否可成功执行并输出符合规范的有效原理图;二是空间违规指标,衡量生成的原理图中符号、标签、导线等元素的重叠情况;三是网表准确性指标,对比生成网表与真实原理图的连接一致性。相关评估在gpt-oss-20B模型上开展,结果显示经过SchGen_dataset微调后的模型,在PCB原理图生成能力上有显著提升。同时官方也明确了该数据集的当前限制:仅可用于研究用途,暂不支持商用落地;数据内容以中小规模原理图模块为主,对射频/高频电路、尖端工业硬件、复杂多板系统的覆盖度有限;所有自然语言请求仅支持英语;部分基于图像/PDF的原理图重建内容可能存在注释或转换误差,因此该数据集不得直接应用于航空航天、医疗电子等安全关键或受高度监管的领域。目前该数据集采用MIT许可证开放下载。
作为工业AI领域少有的高质量垂直场景对齐数据集,SchGen_dataset的发布也为数据要素赋能工业数字化转型提供了典型样本。当前全球数据要素市场正从通用互联网数据向垂直行业高价值数据延伸,电子制造领域的设计数据、生产数据的标准化、开放化,将成为推动产业全链路数字化的核心动力,本次微软发布的数据集也有望带动更多硬件设计领域的高价值数据开放,加速整个电子信息产业的智能化升级。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)