

随着大语言模型在金融投研、宏观策略分析、量化因子挖掘等垂直场景的落地进程加速,行业对标准化、长周期的模型能力评估基准的需求持续高涨。此前金融预测领域的公开基准多以实时更新形态为主,仅能支持当期模型效果校验,无法满足模型迭代过程中的长周期回溯测试、跨经济周期能力验证需求,针对美国成熟宏观市场的结构化评估数据集更是稀缺。
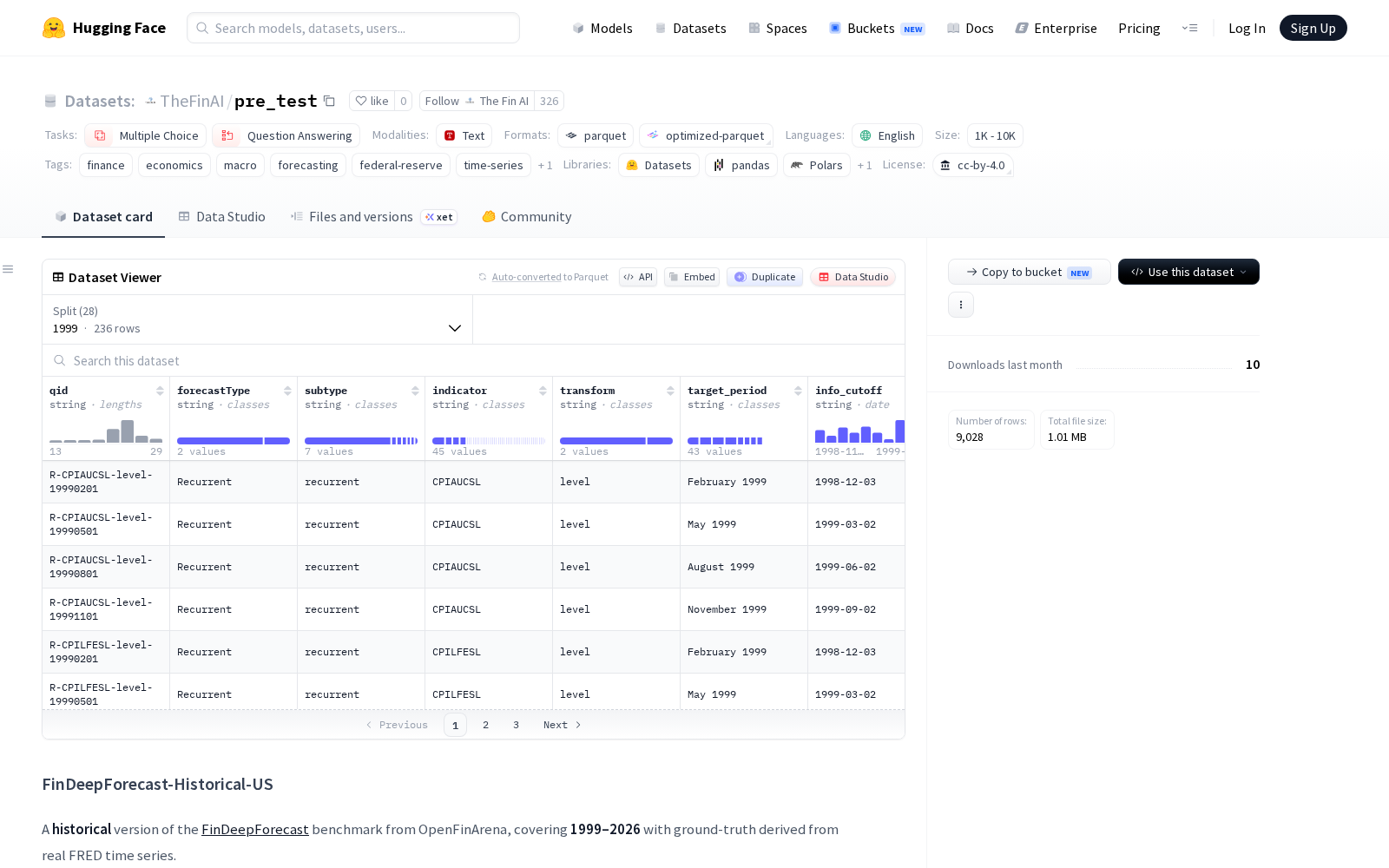
The Fin AI本次发布的pre_test数据集(全称为FinDeepForecast-Historical-US),是OpenFinArena旗下FinDeepForecast实时金融预测基准的历史版本,主要面向宏观经济预测、金融时间序列分析两大应用领域。该数据集覆盖1999 年至 2026 年的完整周期,共包含 8,437 个预测问题,其基准真值全部来源于权威的美国联邦储备经济数据(FRED)时间序列,专为可重复的离线评估场景设计。
在分类设计上,数据集严格遵循原论文的双轨分类法:第一类是占比75.5%的“周期性预测”(Recurrent),共6,366题,涉及对未来特定日期CPI、GDP、国债收益率等核心宏观经济指标数值的预测,全部以4选项多项选择题形式呈现;第二类是占比24.5%的“非周期性预测”(Non-Recurrent),共2,071题,针对FOMC利率决策、CPI/NFP数据发布是否超预期、市场周度阈值等即将发生的特定预定事件进行二元(YES/NO)判断。为方便分周期测试,数据按年份划分为28个独立分片,每年约含300个问题。
从指标覆盖来看,该数据集共涵盖49个美国关键宏观经济与市场指标,分为通胀、劳动力、增长、利率、货币、消费、住房、制造业和市场等九大类,完整覆盖了影响美国宏观经济走势的核心观测维度。每个样本包含15个结构化字段,包括唯一问题ID(qid)、预测类型(forecastType)、细分子类型(subtype)、FRED指标代码(indicator)、目标时期(target_period)、信息截止日期(info_cutoff)、问题文本(question)、选项列表(options)以及答案(answer_letter, answer_raw)等,可直接适配多项选择与问答类模型的评估需求。
从应用价值来看,该数据集旨在为评估大语言模型及其他预测模型在金融时间序列预测和宏观经济事件判断方面的能力提供大规模、高质量的基准。与原始实时基准相比,本历史版本虽然不具备“无法记忆”的实时特性,但提供了长达28年的回溯测试能力,且仅聚焦于美国宏观市场,可应用于金融大模型的微调效果校验、多模型横向能力对比、量化投资策略的宏观因子回测、宏观经济预测领域的学术研究等多个场景,对推动金融垂直大模型的标准化评估、加速大模型在金融场景的落地进程具有重要意义。
Dataset card内容:
Files and versions内容:



_1769672084863.jpg)